Learning to Verify AI-Generated Code
Written by
Xingyao Wang
Published on
LLMs made generating code cheap. The real bottleneck is verification: checking that a change is correct, follows repo conventions, and is something your team can trust, review, and merge.
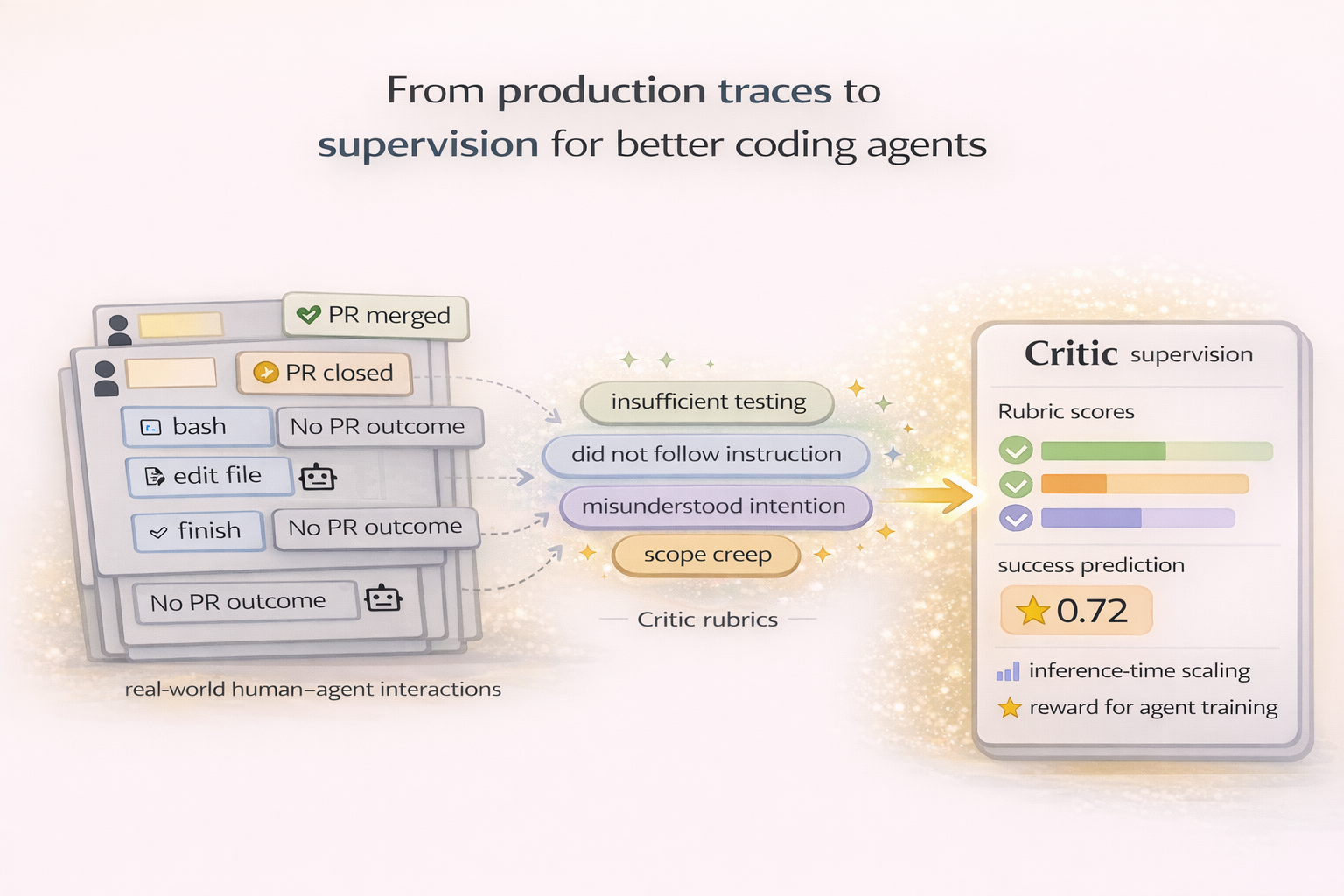
In OpenHands, we think of this as a verification stack: a layered set of verifiers that helps coding agents fail fast and produce changes humans can confidently merge.
This post introduces the first layer of our stack: a trajectory-level verifier implemented as a small, fast critic model. We'll share the second layer of the stack in a follow-up post soon.
What this critic does
The critic scores an agent's trajectory (conversation, tool calls, and actions). You can use it to decide whether to continue, stop, or refine; to pick among multiple attempts; and to collect lightweight feedback that improves the agent over time.
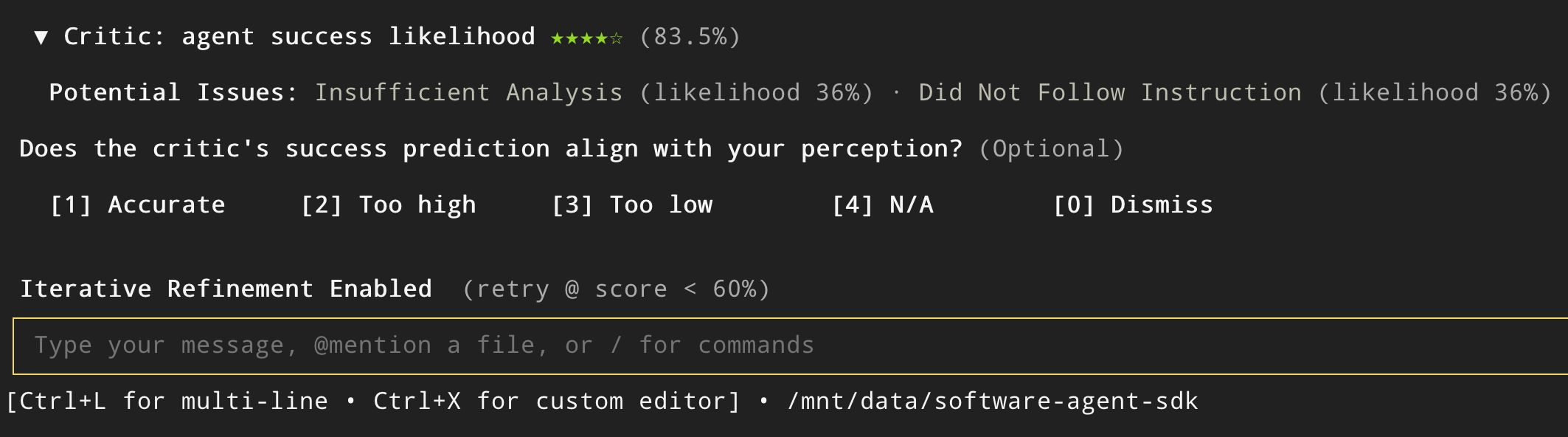
Because the model is small, it's fast (often sub-second to ~1s) and cheap enough to run during an interactive session.
Why production use is different from benchmarks
Previous academic work has trained critic models on datasets like SWE-Bench and SWE-Gym. Training a critic is convenient because you often have verified rewards (e.g., unit tests) to label each attempt as correct or not.
But those verified rewards usually don't exist in real-world, human-in-the-loop development. Production sessions are messy: goals evolve, success signals are sparse or delayed, and what matters is often whether the work survives review and merges.
In practice, we found that critics trained only on benchmark traces translate poorly to production. So this critic is trained on real-world production traces, using sparse signals such as PR merge and code survival.
| Training / signal | AUC on production outcomes |
|---|---|
| Trained on benchmark-style data only | ~0.45-0.48 (worst than random) |
| Trained with production supervision (outcome proxy: PR merge) | 0.58 |
| Trained with production supervision (outcome proxy: code survival) | 0.69 |
That gap is why we train this critic on real-world user–agent interactions. We use the kinds of sparse signals you can actually get in production (PR merge and code survival), and turn traces into dense supervision via rubrics.
How we train it (from production traces)
We train the critic from real-world user–agent interactions using a pipeline that mirrors the figures below.
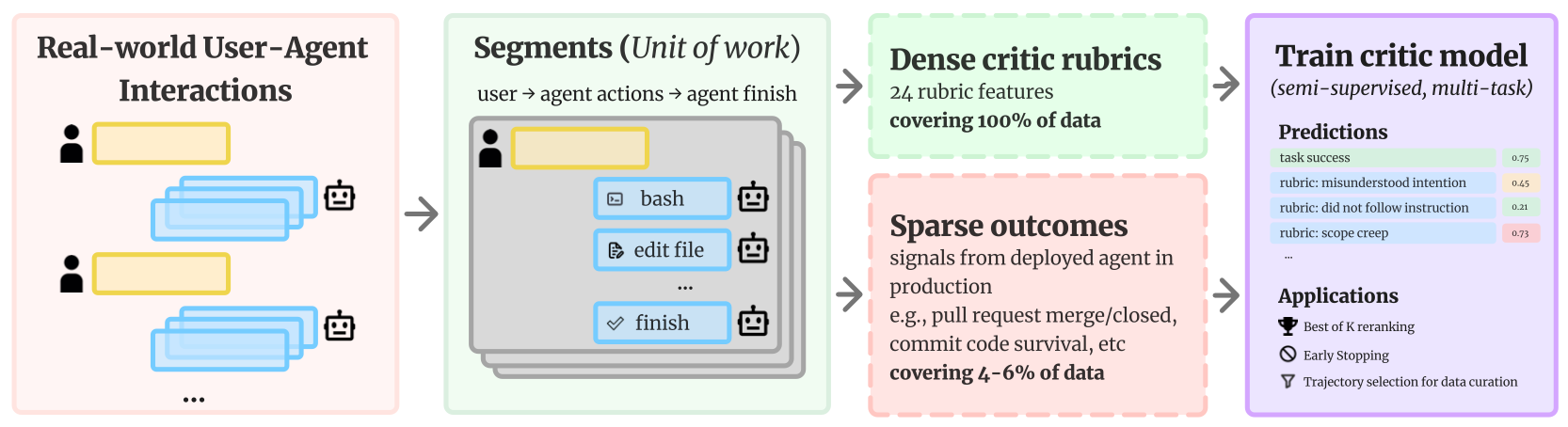
Step 1: Assign credit to agent segments
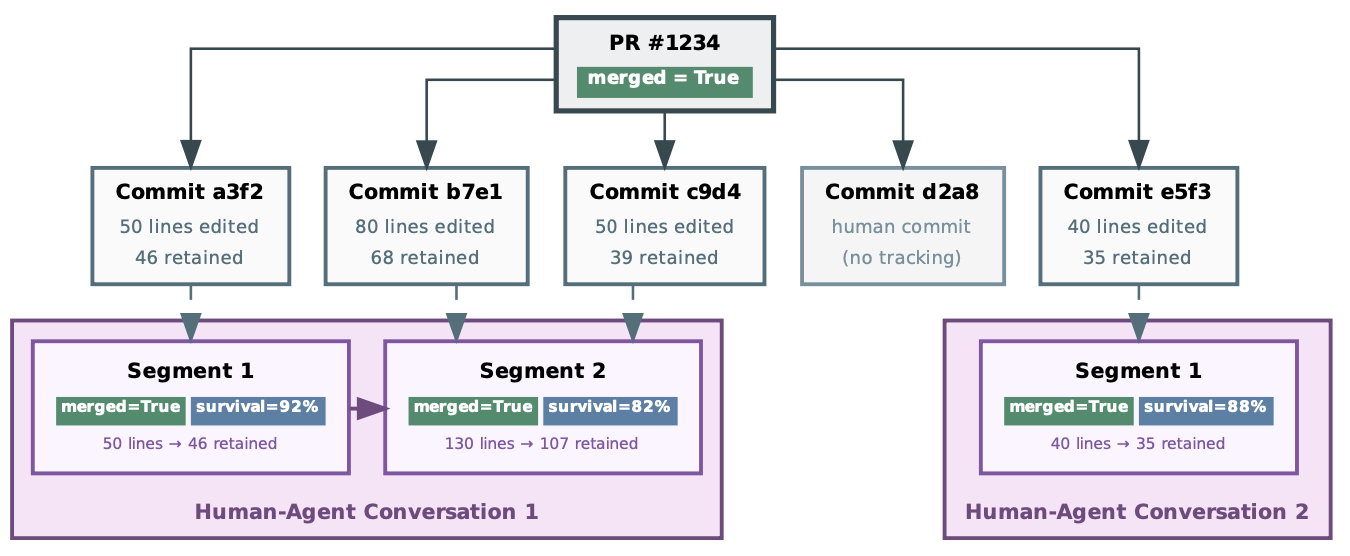
We standardize each interaction into segments: user request → agent actions/tools → finish. Segments are the unit we train and evaluate on, and they're crucial in production, where a single chat often contains multiple "segments/tries."
Step 2: Turn traces into dense supervision
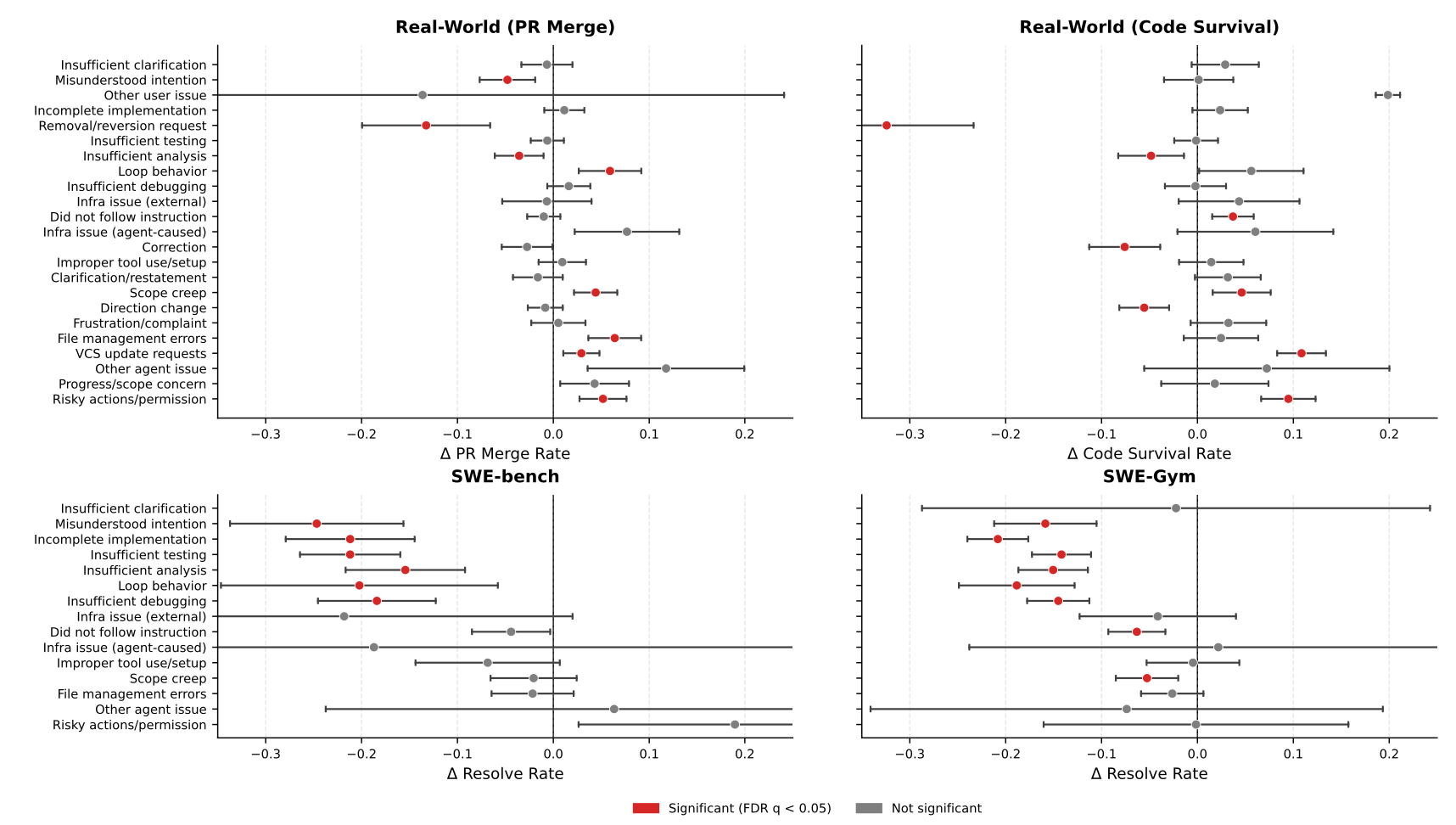
We annotate every segment with Critic Rubrics: 24 trace-observable features describing behavioral quality and common failure modes (misunderstood intent, didn't follow instructions, scope creep, and more). Because they come from the trace itself, this supervision covers essentially 100% of segments.
To validate that this isn't just taxonomy for taxonomy's sake, we run regressions from rubric features to sparse outcomes. The takeaway is that rubrics are predictive of real outcomes, and what's predictive can differ between benchmarks and production.
Step 3: Ground with sparse outcomes, then train the critic
For the small subset of segments where we can align production signals, we attach sparse outcome proxies—primarily code survival (~4% coverage) and PR merge (~6% coverage).
We then train a small semi-supervised, multi-task critic that learns to predict rubric features (dense) and success from outcome proxies (sparse), turning previously unlabeled segments into usable training data.
Does it work? Key evaluation takeaways
We structure the evaluation into two parts.
First, we evaluate the critic itself: real-world supervision is necessary, and critics trained only on benchmark-style datasets are near-random on real-world outcomes (AUC ~0.45–0.48). Outcome proxies also matter—despite being sparser, code survival is a stronger training signal than PR merge (intrinsic AUC 0.69 vs 0.58).
Then, we evaluate the finalized critic on downstream inference-time scaling, in two modes we use in practice: Best-of-N Selection (rerank multiple attempts and pick the best) and Early Stopping (accept as soon as the score clears a threshold). Unless otherwise noted, the downstream results below use our best-performing supervision setup—code survival as the outcome proxy, with rubric supervision enabled (motivated by the intrinsic AUC comparison above).
The payoff shows up at inference time. On the mixed-outcome subset of SWE-bench Verified (instances where at least one run succeeds and at least one fails), critic-guided selection substantially improves inference-time scaling (Best@8 73.8% vs Random@8 57.9%) and makes early stopping cheaper (+17.7 over random with 1.35 attempts on average).
| Selection mode | Metric | Random | Critic (trained on code survival + rubrics) |
|---|---|---|---|
| Best-of-N Selection | Best@8 (mixed-outcome SWE-bench) | 57.9% | 73.8% |
| Early Stopping | Δ vs random | 0.0 | +17.7 |
| Early Stopping | Avg attempts | 8.0 | 1.35 |
For the full ablation grid and additional details, please refer to our paper.
Try it today
OpenHands SDK
The critic is integrated into the OpenHands Software Agent SDK, so you can call it programmatically and use the score in your own loops (e.g., reranking, early stopping, iterative refinement).
SDK guide: https://docs.openhands.dev/sdk/guides/critic
OpenHands CLI
The critic + early stopping (accept as soon as the score clears a threshold) is also integrated into the OpenHands CLI (free when using the OpenHands Model Provider). You can enable it, perform iterative refinement with it, and optionally configure different acceptance thresholds.
CLI guide: https://docs.openhands.dev/openhands/usage/cli/critic
What's next
This post covered layer one: judging an entire trajectory. Layer two is more surgical—it focuses on catching patch-level issues early (repo conventions, common footguns, and the kinds of problems that waste reviewer time). We'll publish a follow-up post soon that introduces layer two and shows how it composes with the critic.
In the meantime, here are the best places to go deeper or try it yourself:
-
Docs:
-
SDK guide: https://docs.openhands.dev/sdk/guides/critic
-
CLI guide: https://docs.openhands.dev/openhands/usage/cli/critic
-
Paper (arXiv): https://arxiv.org/abs/2603.03800
-
Model weights: https://huggingface.co/OpenHands/openhands-critic-4b-v1.0
-
Code / GitHub repo: https://github.com/OpenHands/critic-rubrics
If you're deploying OpenHands in a team setting and want critic-based verification wired into your workflow (policy checks, custom thresholds, feedback pipelines), reach out—we're happy to help.

Get useful insights in our blog
Insights and updates from the OpenHands team
Sign up for our newsletter for updates, events, and community insights.
OpenHands is the foundation for secure, transparent, model-agnostic coding agents - empowering every software team to build faster with full control.



