EvoClaw: Evaluating AI Agents on Continuous Software Evolution
Written by
Gangda Deng and Zhaoling Chen
Published on
This is a guest blog by Gangda Deng and Zhaoling Chen, introducing EvoClaw—a benchmark built with OpenHands to move beyond isolated coding tasks and toward continuous software evolution.
AI coding has entered a new phase. In early 2026, stronger LLMs and projects like OpenClaw started pushing agents toward long-running, iterative workflows instead of one-off conversational task solving.
Most benchmarks still evaluate isolated tasks. Agents are getting good at those. But real engineering work is not one isolated task. Teams continuously extend an existing codebase while preserving behavior, managing dependencies, and paying down technical debt.
Continuous development is where software engineering really begins. Early implementation choices constrain later work, regressions accumulate, and the real question becomes: can an agent keep solving the next task without degrading the system in the process?
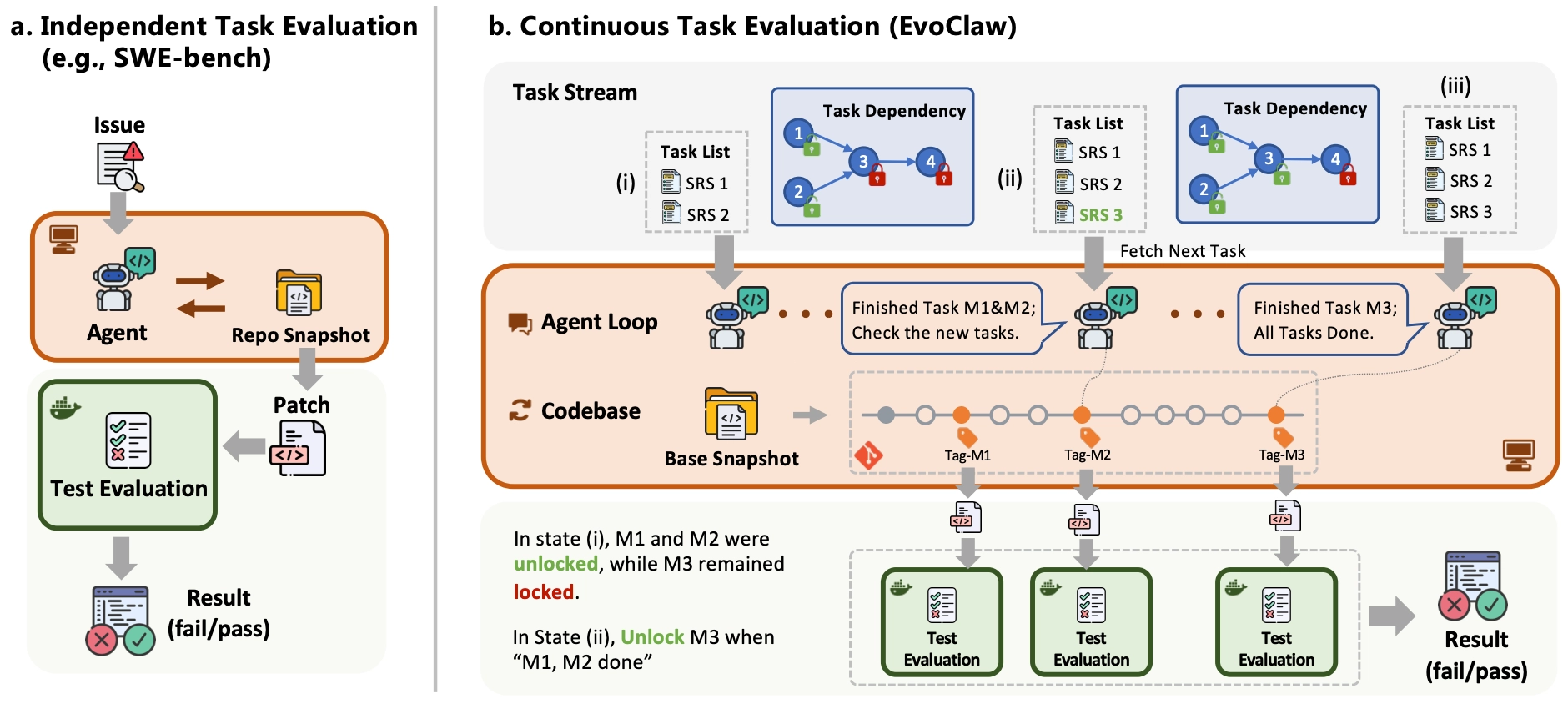
That is what EvoClaw is designed to measure. It evaluates agents on continuous software evolution by asking them to complete a sequence of dependent milestone tasks extracted from real repository history.
From isolated tasks to continuous evolution
EvoClaw is built around a simple observation: one-shot code generation is not how most software is developed. Requirements arrive over time, each change depends on earlier decisions, and the system has to stay healthy while it evolves.
The benchmark captures that setting by reconstructing milestone trajectories from real repositories and evaluating agents across those trajectories instead of on isolated bug-fix prompts.
Why milestones matter
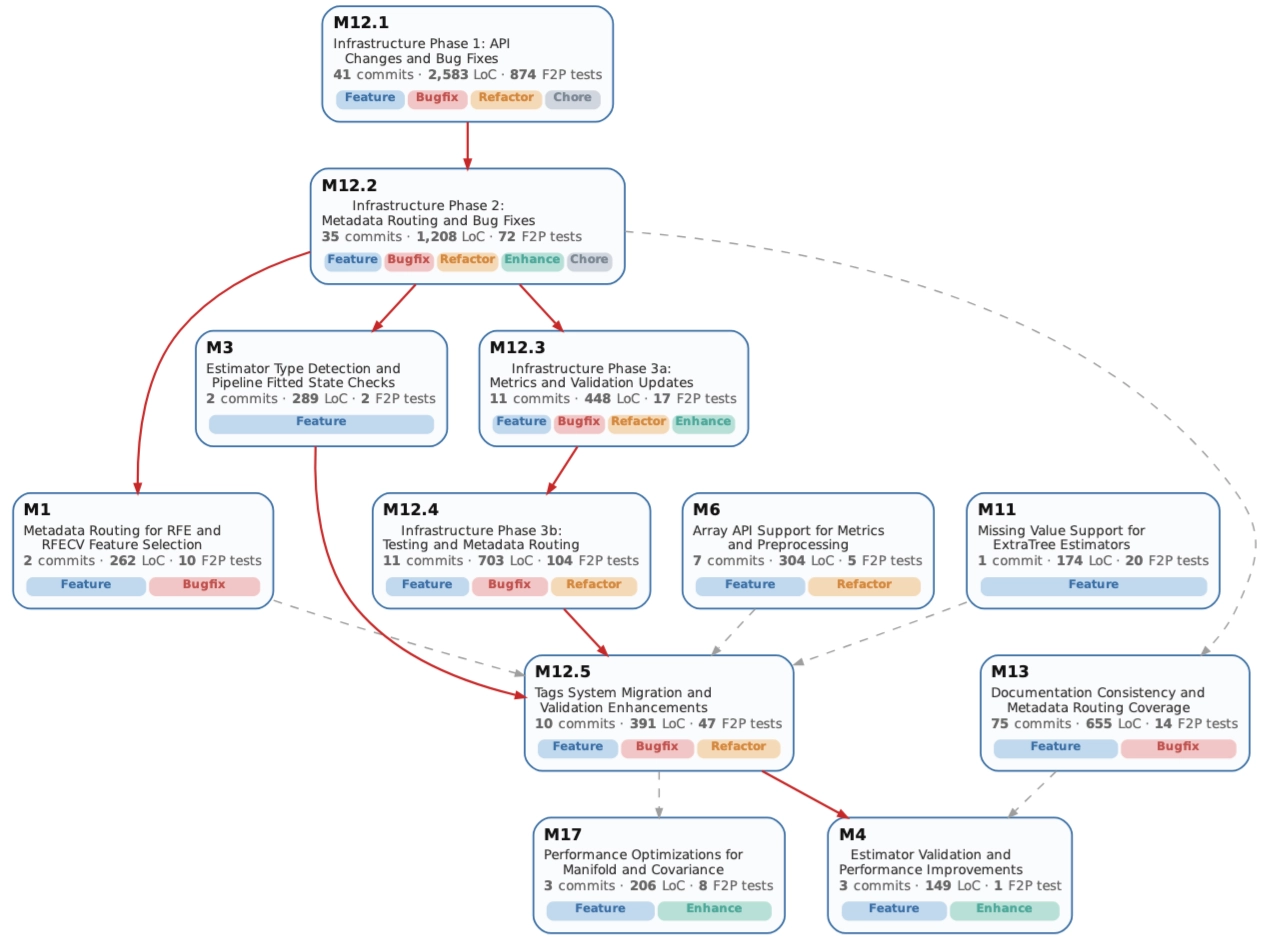
Milestone-level task granularity is the key design choice in EvoClaw.
A single commit is often too small and too noisy to serve as a meaningful development objective. At the other extreme, release-level changes are too coarse and hide the dependency structure that makes long-horizon maintenance difficult. EvoClaw works at the milestone level: semantically and functionally coherent units that are still executable and testable.
To build those trajectories at scale, the authors introduce DeepCommit. Starting from real open-source history, DeepCommit aggregates related commits into milestones, infers temporal dependencies, and validates the resulting task graph at runtime.
What EvoClaw measures
EvoClaw covers repositories across five programming languages. For each repository, it selects a real development window spanning multiple releases, sometimes across as much as 750 days of history.
The benchmark focuses on two complementary dimensions:
-
Recall: how much of the newly required functionality the agent implements
-
Precision: how much existing functionality the agent preserves without introducing regressions
Those two signals are then combined into a milestone-level score using an F1-style aggregation.
This framing matters because the hard part of real software evolution is often not adding new code. It is keeping the existing system from breaking while the codebase gets more complicated.
The headline result
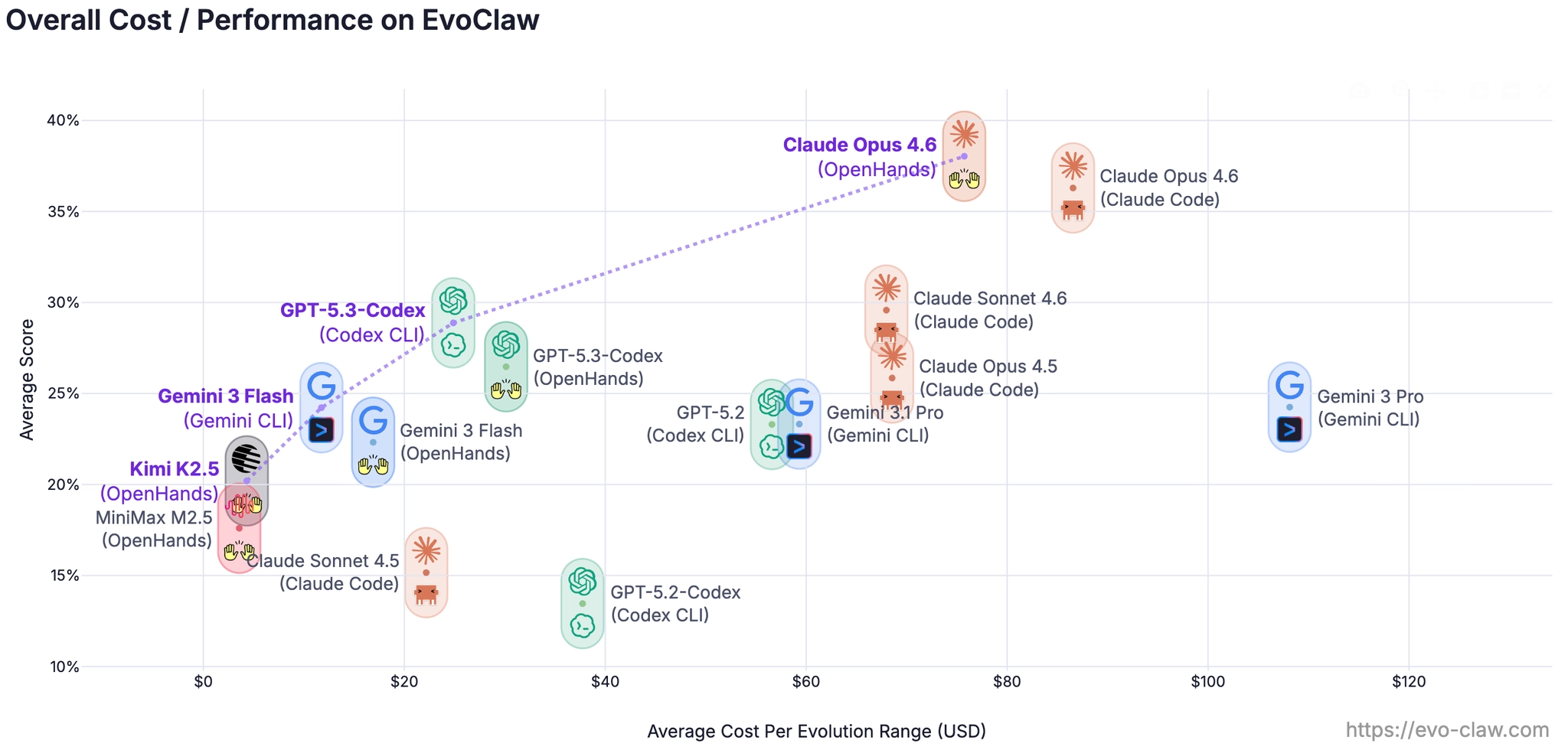
The results drop sharply once evaluation moves from isolated tasks to continuous evolution.
On isolated-task settings, frontier agents can often score above 80%. But under EvoClaw's continuous setting, the best system in the initial release reaches only 38.03% overall score: Claude Opus 4.6 + OpenHands. The highest resolve rate is 13.37%, achieved by Gemini 3 Pro + Gemini CLI.
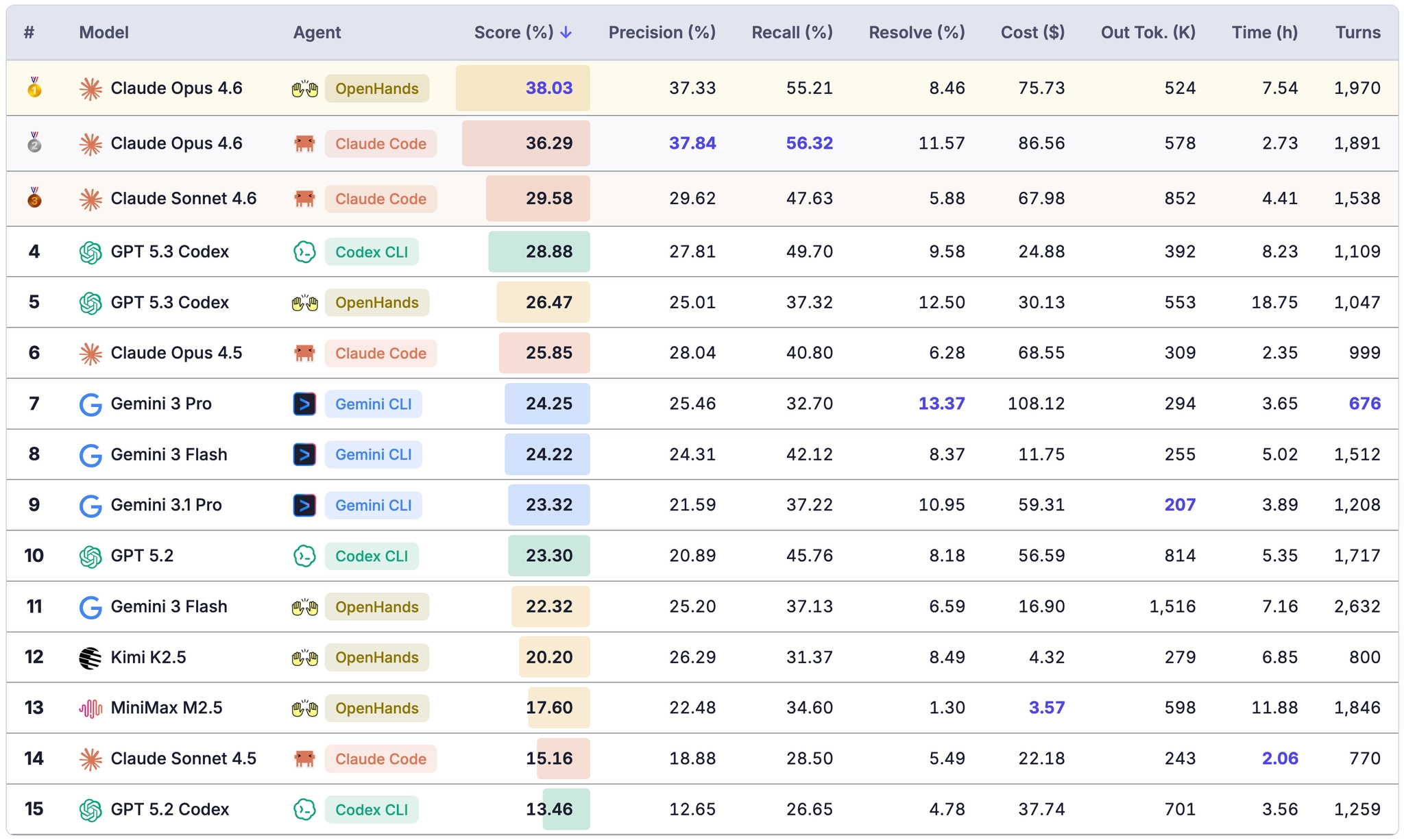
That gap is the central point of the benchmark: isolated-task performance still overestimates how well an agent will behave once earlier choices, regressions, and dependency chains start to matter.
Evolution eventually stalls
A natural question is whether a strong coding agent could eventually finish the whole project if you simply gave it enough iterations.
EvoClaw suggests the answer is no.
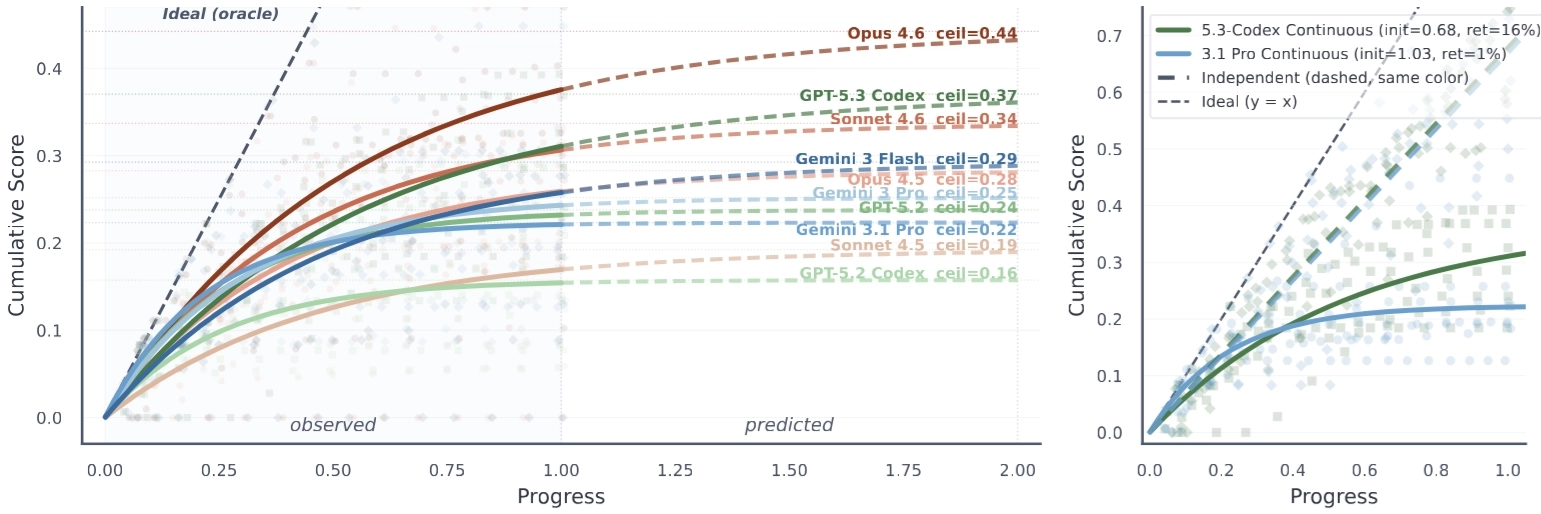
Even the strongest system, Opus 4.6, plateaus at roughly 45% overall score under saturation-based extrapolation. The differences across model families are also revealing: GPT and Claude improve steadily across versions, while Gemini variants often start faster in the early milestones but show much less long-horizon improvement.
A more interesting pattern appears when the overall score is decomposed into recall and precision.
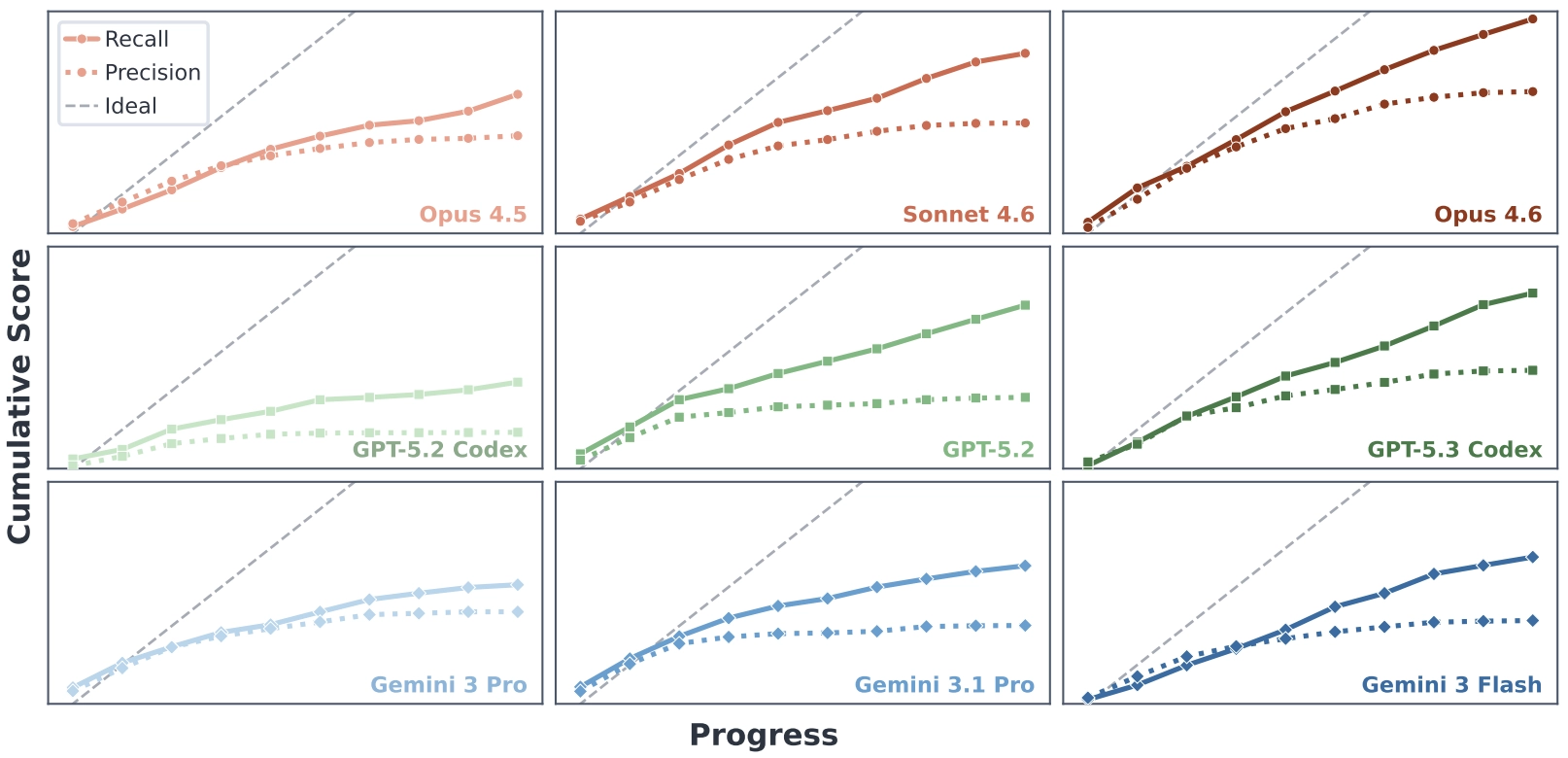
Recall keeps rising almost linearly. Even as the codebase becomes messier and more fragile, agents remain fairly good at implementing new requested functionality. The bottleneck is precision: models struggle to preserve existing behavior, and regressions accumulate faster than they can be repaired.
That is what ultimately causes long-horizon development to stall.
Technical debt compounds faster than agents can repair it
To understand how failures compound over time, the benchmark introduces an error chain analysis that tracks how problems propagate across milestones.
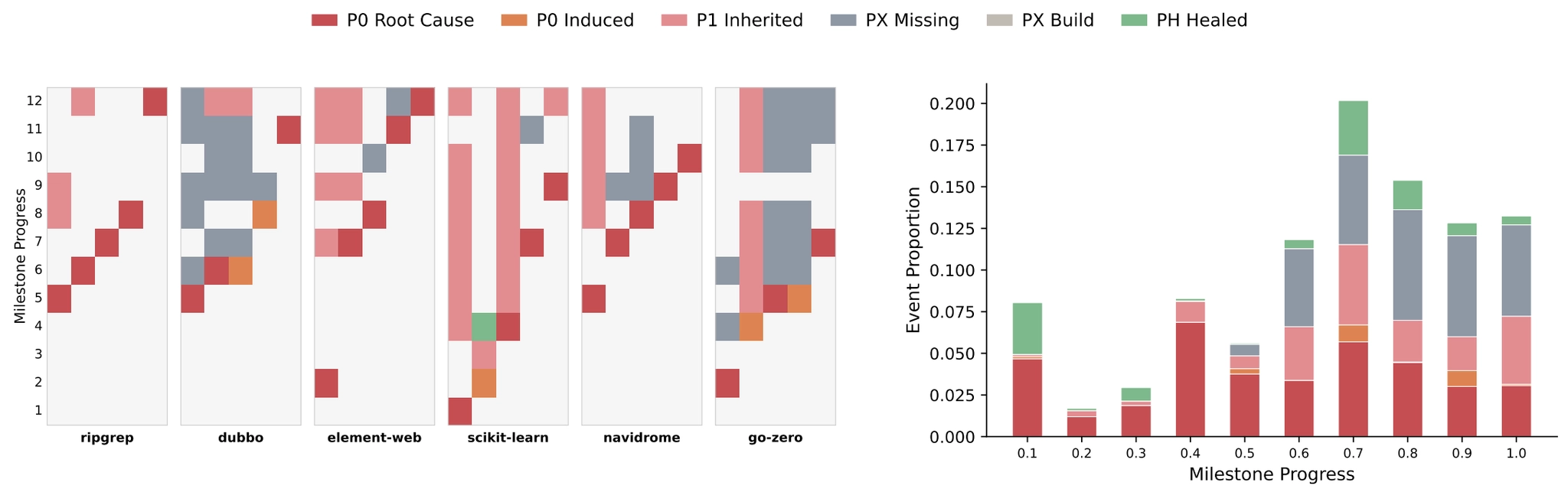
The pattern is clear. Agents do sometimes repair earlier mistakes, but unresolved regressions accumulate faster than they can be fixed. Those failures then propagate downstream through dependency chains, creating a snowball effect that eventually stalls further progress.
From code generation to system governance
If EvoClaw makes one thing clear, it is that code generation alone is not enough. The real entry point for AI systems into software engineering is whether they can follow evolving requirements while also keeping the larger system stable.
Today's frontier models still behave more like on-demand code generators than like senior engineers maintaining a living codebase. They are much better at local implementation than at system-level judgment.
That points to where the next breakthroughs need to happen: proactive refactoring, long-term memory, better planning, and much stronger awareness of architectural state. It is the same shift described in The Second Half: moving from passive code generation toward active system governance.
If you want to dig deeper, the full project is available here:
.png)

Get useful insights in our blog
Insights and updates from the OpenHands team
Sign up for our newsletter for updates, events, and community insights.
OpenHands is the foundation for secure, transparent, model-agnostic coding agents - empowering every software team to build faster with full control.



