Effective Strategies for Asynchronous Software Engineering Agents
Written by
Jiayi Geng
Published on
This guest blog by Jiayi Geng of Carnegie Mellon University introduces CAID, a multi-agent system built on OpenHands that uses git worktrees, branches, merges, and tests to coordinate long-horizon software engineering tasks.
AI coding agents have gotten remarkably good at isolated tasks like resolving GitHub issues. But the tasks we actually want agents to do are getting larger. For example, building a Python library from scratch (Commit0) or reproducing the results of a research paper (PaperBench) involves dozens of interdependent subtasks that unfold over hours. A single agent working on these tasks struggles both with accuracy and with wall-clock time.
A natural solution is to have multiple agents work in parallel on different parts of the task. But multi-agent collaboration on a shared codebase has proven surprisingly fragile. The central difficulty is integration. Imagine that two agents each produce correct code independently, but when their changes are combined, the result breaks. One agent renames a function while another writes new code calling the old name. Both complete their work successfully in isolation. The merged result fails to run. These conflicts surface only at integration time, and the fix is rarely a one-line patch.
In our paper Effective Strategies for Asynchronous Software Engineering Agents, we introduce CAID, a multi-agent system built on top of OpenHands that tackles this problem by grounding agent coordination in the same primitives human engineering teams already use: git worktrees, branches, merges, and test-based verification.
Human developers solved this decades ago
Human engineering teams face exactly these coordination problems every day, and they already have mature infrastructure for them. Developers work in isolated copies of the repository via git worktrees, so parallel edits never overwrite each other. Changes are integrated through merge workflows that surface conflicts explicitly. Dependency graphs determine which modules can be developed in parallel and which must wait. Test suites verify each change automatically.

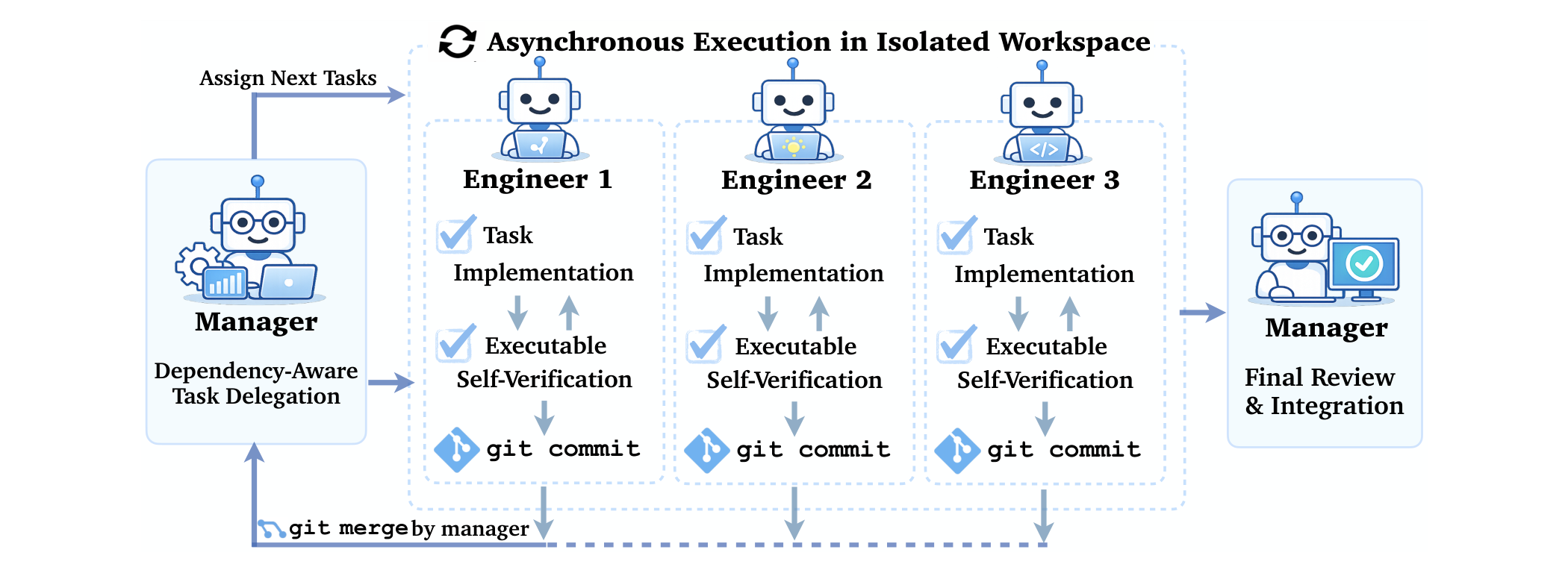
Prior multi-agent systems usually rely on free-form chat between agents or ad hoc coordination protocols. CAID takes a different approach: it maps each of these established software engineering primitives directly onto a multi-agent coordination mechanism. A manager agent decomposes tasks and builds a dependency graph. Multiple engineer agents each work in their own git worktree. Completed work is merged back via git merge. And test suites provide automated verification at every step.
How CAID works
The manager starts by exploring the task specification and constructing a dependency graph that identifies which subtasks can be executed in parallel and which must wait for upstream work. It then creates an isolated git worktree for each engineer and assigns a specific subtask along with structured JSON instructions.
Each engineer works independently in its own worktree: implementing, running tests, and committing. When any engineer finishes, the manager merges its branch back into main, resolves conflicts if needed, and dynamically updates the task plan based on the current state of the codebase before assigning the next subtask. After all tasks are complete, the manager does a final review and submits. All communication between manager and engineers goes through structured JSON and git commits, not free-form dialog.
Branch-and-merge based coordination improves multi-agent performance
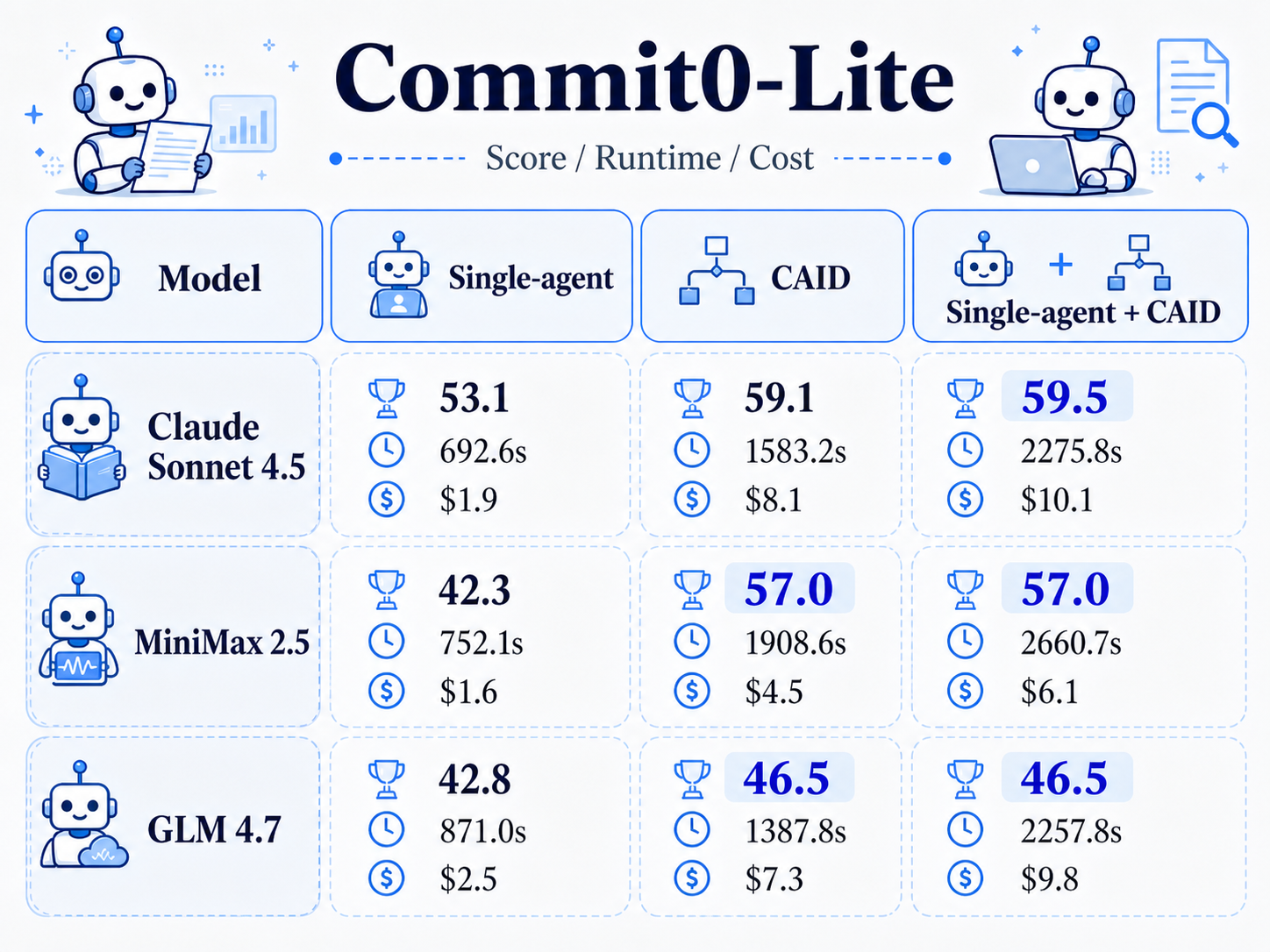
We evaluate CAID on two long-horizon benchmarks. Commit0 requires agents to implement Python libraries from scratch such as tinydb, minitorch, and jinja. PaperBench requires agents to reproduce the main contributions and results of a research paper.
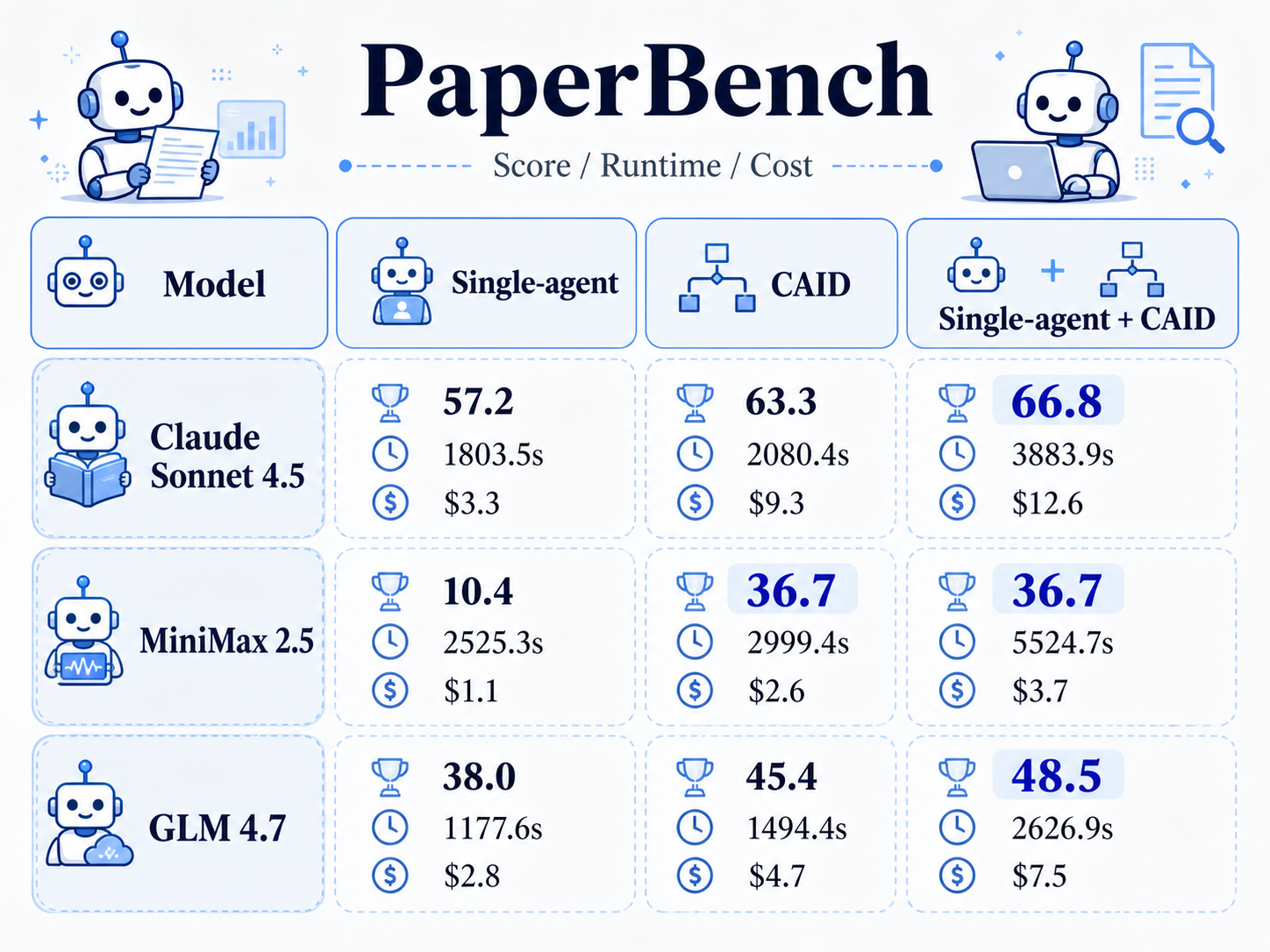
On Commit0, CAID improves over the single-agent baseline by 14.3% absolute. On PaperBench, the improvement is 26.7%. These gains are consistent across three different language models: Claude 4.5 Sonnet, GLM 4.7, and MiniMax 2.5. The improvement is not tied to a specific model family. The branch-and-merge coordination pattern helps regardless of which model is doing the actual coding.
Single agents fail to utilize more iterations
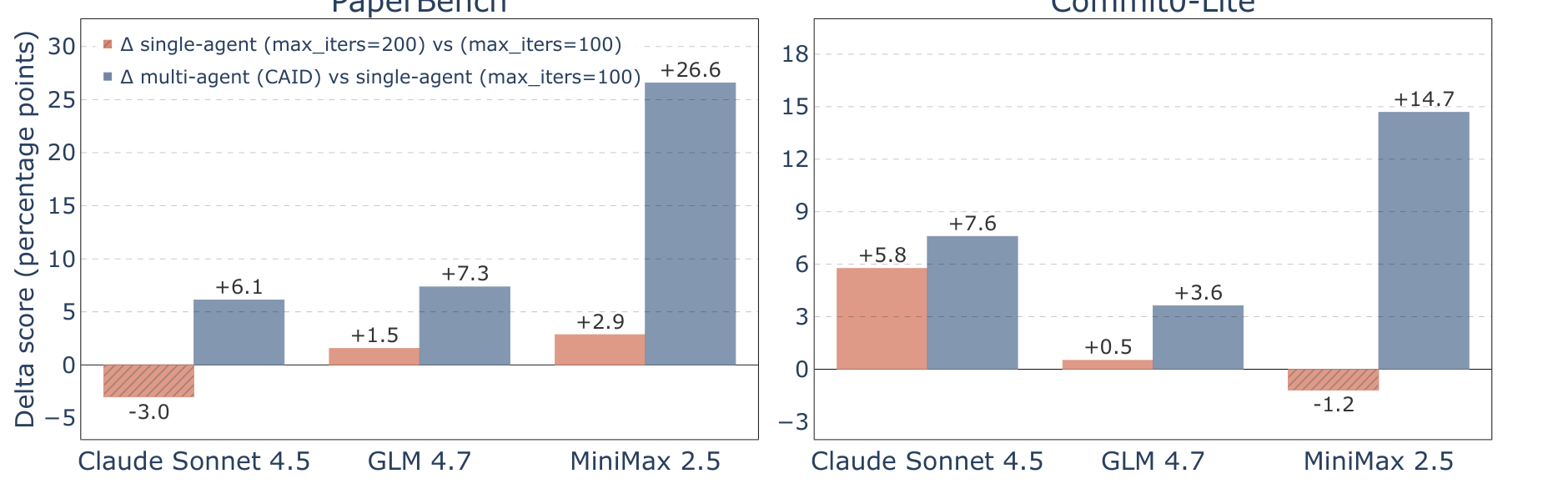
A natural objection is that multi-agent systems simply use more total compute. What if we gave a single agent the same additional budget by letting it run for more iterations?
The answer is that it does not help. Single agents plateau after a certain number of iterations. Additional steps are spent going in circles, revisiting earlier decisions, or making changes that break previously working code. The extra compute is largely wasted.
Multi-agent systems, by contrast, continue to benefit from additional resources because independent subtasks can genuinely progress in parallel. The bottleneck for single agents is not compute but the serial nature of the work: one agent cannot effectively context-switch across many interdependent subtasks the way a coordinated team can.
Isolation is what makes it work
The ablation study is another case where the table is more informative than the image. Bolded scores mark the stronger configuration in each benchmark.

What specifically about CAID's design drives the improvement? We ablate the key components to find out.
Removing git worktree isolation and letting multiple agents edit the same workspace causes a significant performance drop. Without isolation, agents' edits interfere with each other in exactly the ways described earlier. Isolation is not an engineering convenience. It is the prerequisite for multi-agent collaboration to work at all.
We also examine how performance scales with the number of parallel agents. Adding more agents helps up to a point, but returns diminish as the number of agents exceeds the number of parallelizable subtasks in the dependency graph. This matches the intuition from human teams: adding engineers speeds things up only as long as there is independent work for them to do.
When single agents hit a ceiling on long-horizon tasks, try CAID
Our work suggests a practical shift in how to deploy coding agents on complex tasks. The conventional approach is to start with a single agent and escalate to multi-agent only after repeated failure. Our results suggest that the escalation should happen earlier, and that CAID is a reasonable thing to reach for. Once a single agent has stalled on a long-horizon task, the next thing to try is not another single-agent run with a larger budget. It is CAID.
If you want to dig deeper, the project is available here:
References
-
J. Geng and G. Neubig. 2026. Effective Strategies for Asynchronous Software Engineering Agents. arXiv preprint arXiv:2603.21489.
-
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Li, H. Chen, K. Narasimhan, and O. Press. 2023. SWE-bench: Can language models resolve real-world GitHub issues? arXiv preprint arXiv:2310.06770.
-
X. Wang, B. Li, Y. Song, F. F. Xu, X. Tang, M. Zhuge, J. Pan, Y. Song, B. Li, J. Singh, et al. 2024. OpenHands: An open platform for AI software developers as generalist agents. arXiv preprint arXiv:2407.16741.
-
W. Zhao, N. Jiang, C. Lee, J. T. Chiu, C. Cardie, M. Gallé, and A. M. Rush. 2024. Commit0: Library generation from scratch. arXiv preprint arXiv:2412.01769.
-
G. Starace, O. Jaffe, D. Sherburn, J. Aung, J. S. Chan, L. Maksin, R. Dias, E. Mays, B. Kinsella, W. Thompson, et al. 2025. PaperBench: Evaluating AI's ability to replicate AI research. arXiv preprint arXiv:2504.01848.

Get useful insights in our blog
Insights and updates from the OpenHands team
Sign up for our newsletter for updates, events, and community insights.
OpenHands is the foundation for secure, transparent, model-agnostic coding agents - empowering every software team to build faster with full control.



