OpenHands Context Condensensation for More Efficient AI Agents
Written by
Calvin Smith
Published on
Today we're excited to introduce the OpenHands context condenser, a significant advancement in our agent architecture that addresses one of the most persistent challenges in AI agent development: managing growing conversation context efficiently.
Our new condenser implementation achieves:
-
💰 Up to 2x per-turn API cost reduction
-
⚡ Consistent response times in long sessions
-
🧠 Equivalent (or better!) performance on software engineering tasks
Let's dive into why this matters, how it works, and the impressive results we're seeing.
The Context Growth Problem
If you've used OpenHands or other AI agents for long-running, complex tasks, you've likely encountered this scenario: as your conversation grows, the agent becomes noticeably slower and less responsive. This has negative impacts on:
-
Response Speed: Larger contexts take longer to process
-
Operating Costs: More tokens means higher API costs
-
Effectiveness: LLMs are less effective with lots of irrelevant info in the context
One solution is to start a new chat, but this approach sacrifices continuity and forces users to manually maintain context across sessions.
Our Solution: Intelligent Context Condensation
The OpenHands context condenser maintains a bounded conversation size while preserving the essential information needed to continue discussions effectively.
As the conversation grows beyond a certain threshold, we intelligently summarize older interactions while keeping recent exchanges intact. This creates a concise "memory" of what happened earlier without needing to retain every detail.
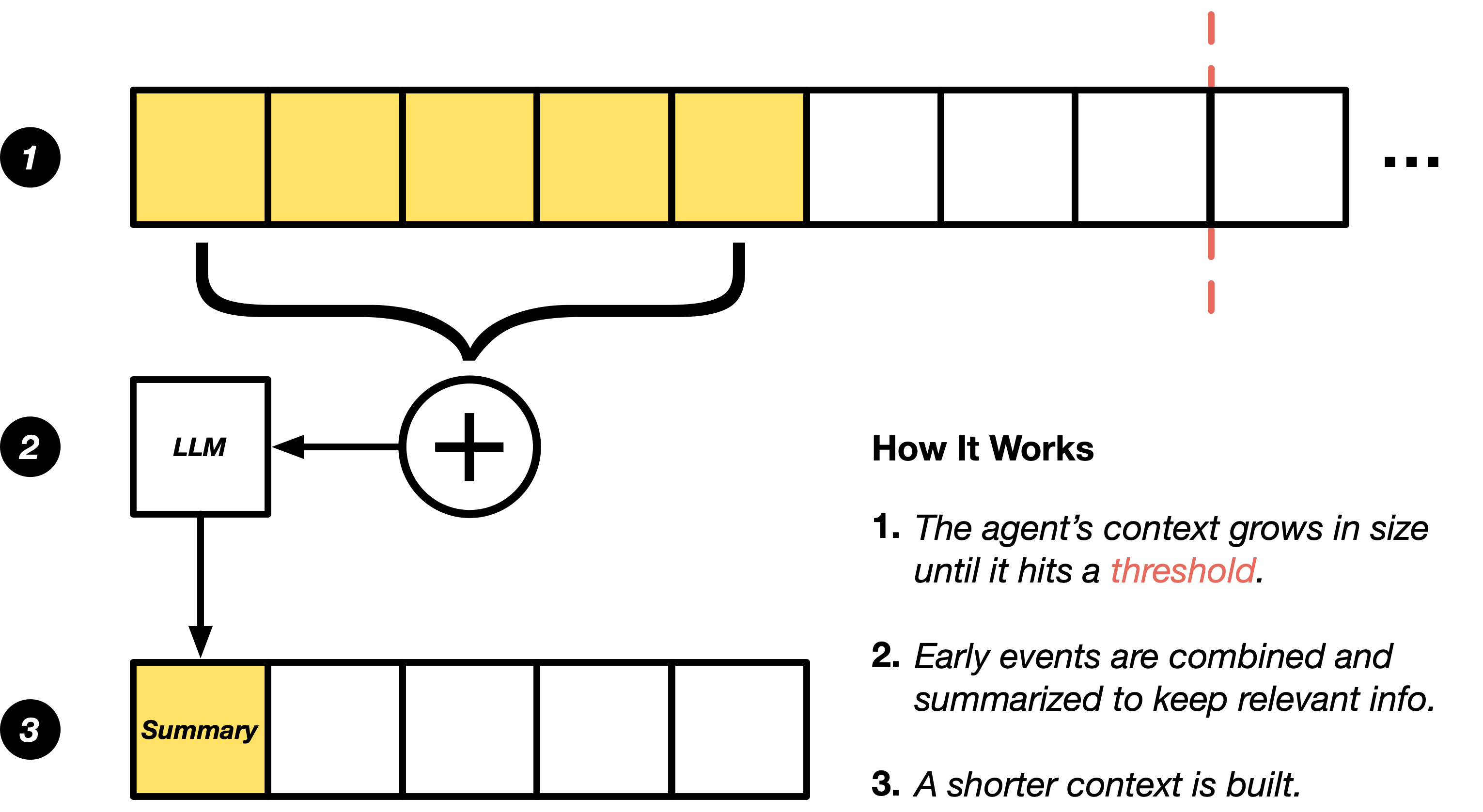
The summarization focuses on encoding the user's goals, the progress the agent has made, and what still has to be done. For software development tasks it also preserves technical details like critical files and failing tests.
This approach maintains the agent's effectiveness while dramatically reducing context size - the agent can remember what matters without the overhead of processing every historical interaction.
Optimizing for Cache Efficiency
A key detail in our implementation is how we handle prompt caching. Most LLM frameworks cache prompts to avoid reprocessing identical content, which significantly improves performance.
Condensation only triggers when the context reaches a specific size, giving us the best of both worlds: we get the benefits of condensation for managing context size while still leveraging cache efficiency by amortizing rebuilding costs across multiple turns.
When events are of similar size, this approach transforms the scaling properties of the system. Baseline context management without condensation scales quadratically over time, while our condensed approach scales linearly - leading to enormous efficiency gains in longer conversations.
Major Efficiency Gains Without Compromising Performance
We evaluated our context condensation strategy against the baseline OpenHands agent on a subset of SWE-bench Verified instances, examining both performance and efficiency metrics.
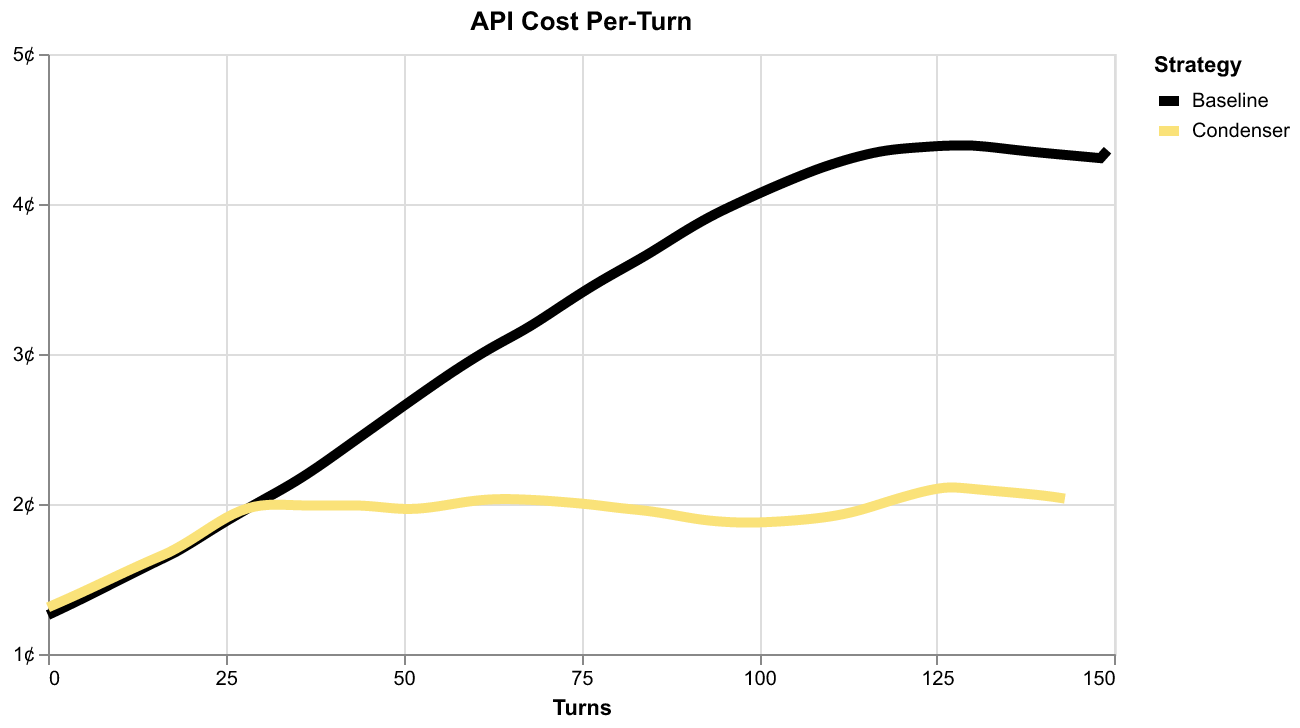
The impact on average API costs per-turn is dramatic:
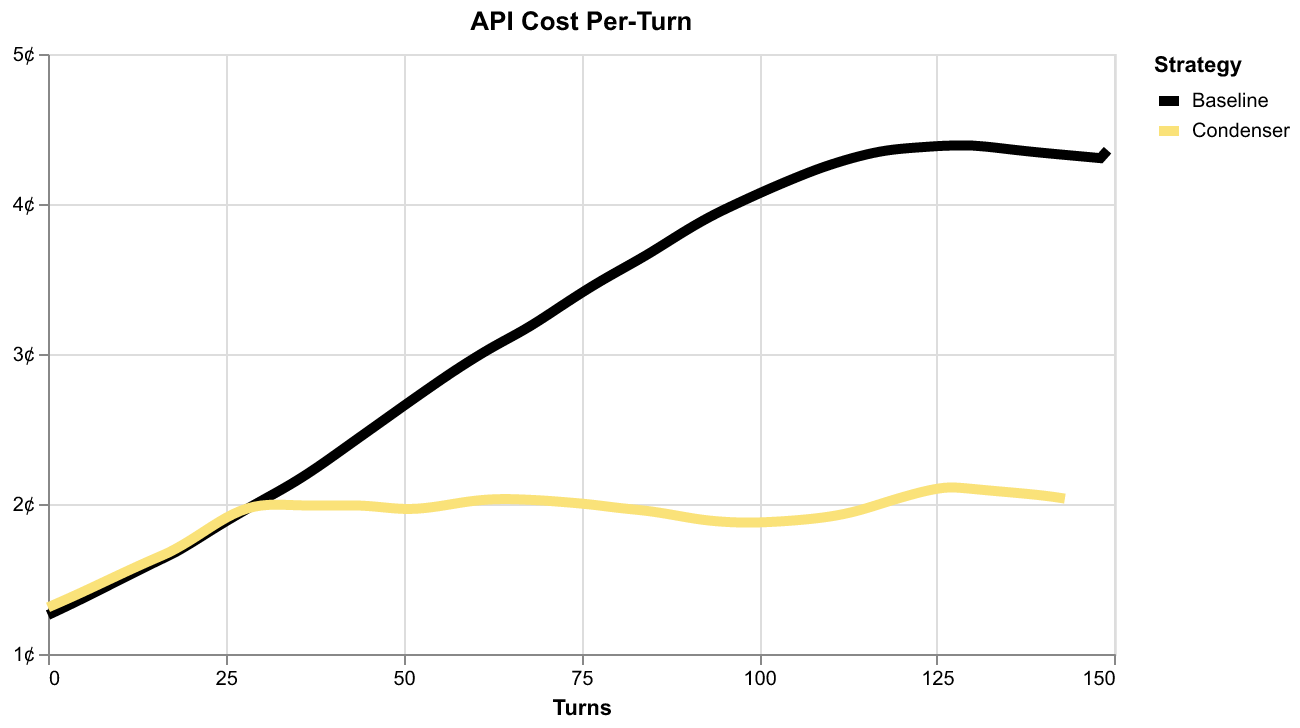
Once context condensation kicks in, the average cost per-turn starts diverging from the baseline until it settles into less than half the cost. This is the scaling behavior mentioned earlier: the baseline agent's per-turn costs keep increasing, while the context condensation keeps them bounded.
Condensation doesn't just use fewer resources, it uses them more efficiently:
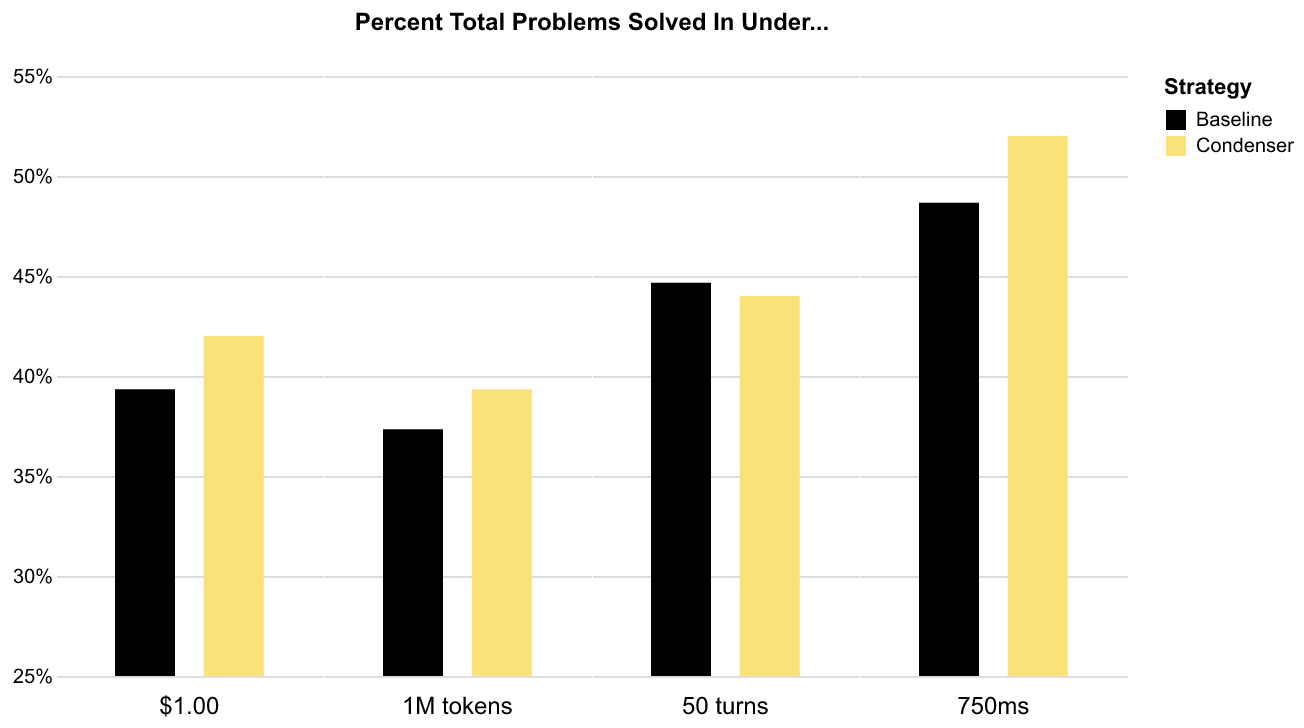
Compared to the baseline, context condensation solves a larger percentage of the SWE-bench problems using less money, fewer tokens, and less completion time - and these trends hold regardless of the breakpoints chosen. The only trade-off is with respect to the number of turns, but this is because the agent occasionally needs a turn to condense the context.
Most importantly, these efficiency gains come without compromise. On the subset tested, the context condensation strategy solves an average of 54% of instances, while the baseline agent only solves an average of 53%.
Try OpenHands Today
Context condensation is available in OpenHands today. To try it out:
-
Start with OpenHands Cloud: The easiest way to get started is with our fully managed cloud solution with seamless GitHub integration, mobile support, and optimizations like context condensation ready to use.
-
Contribute to Open Source: Star our GitHub repository and help advance the frontier of open-source AI software development.
-
Join Our Community: Connect with us on Slack, read our documentation, and stay updated on our latest developments.
We can't wait to see what you'll build with OpenHands!


Get useful insights in our blog
Insights and updates from the OpenHands team
Sign up for our newsletter for updates, events, and community insights.
OpenHands is the foundation for secure, transparent, model-agnostic coding agents - empowering every software team to build faster with full control.



