Introducing the OpenHands Index
Written by
OpenHands Team
Published on
Introducing The OpenHands Index
AI agents are now accelerating all aspects of software engineering, from fixing issues, to building new frontend apps, debugging software, and more. These agents are powered by language models, which each have different strengths, weaknesses, and costs of operation. However, up until this point there was no rigorous way to know the ability of various language models across all these different aspects of software engineering.
Today, we are happy to introduce the OpenHands Index, the first broad-coverage, continually updated leaderboard that evaluates a variety of language models over a broad variety of software engineering tasks. We evaluate them with respect to ability, cost, and run time across 5 different tasks: issue resolution, greenfield apps, frontend development, software testing, and information gathering. This gives coding agent users the ability to choose the best model based on their priorities and use cases. Read on for more!
Why Build This?
When using AI agents for software engineering, we have two choices: which coding agent to use, and which language model to use to power that agent.
For some popular coding agents such as Claude Code by Anthropic and the Codex CLI by OpenAI, the answer about what language model to use is easy. These agents are created by the language modeling companies themselves, and because of this they are language model specific — they basically only support one language model family well.
On the other hand, other coding agents like OpenHands and OpenCode are language model agnostic, they can be used with a wide variety of models. This has a large number of benefits — some language models are better at some things than others, so having the ability to switch between the models allows you to, for example, switch to one model for architectural planning, another model for actual implementation, and yet another for code review and testing. But this is a double-edged sword! Unless you’re a language model connoisseur, it makes it more difficult to decide which model to use in the first place.
Current solutions for benchmarking typically are limited in scope. The popular SWE-Bench Leaderboard, for instance, considers only issue resolution on open-source Python repositories. But there is a lot more to software engineering than this — that is what the OpenHands index tests.
The Benchmark
When setting up a benchmark for language models in agentic tasks, there are two decisions to make. The first is what agent framework to use, and the second is which dataset(s) to include.
For our agent framework, as the benchmark name suggests, we use the OpenHands Software Agent SDK, a production grade agent framework that is both used widely in real-world applications and research.
For datasets, we took a systematic approach. First, we looked at statistics from production traffic to the OpenHands Cloud, found several important areas where users tend to rely on coding agents to perform work. Within each area, we found a representative dataset that we could evaluate on:

-
Issue Resolution: One major class of coding tasks is fixing issues, such as those posted on GitHub. For this, we use the common SWE-Bench-Verified benchmark.
-
Greenfield Development: This includes creating applications from scratch over long horizons. We test this using the commit0 benchmark.
-
Frontend Development: A common use case for “vibe coding”, this involves making improvements to frontend apps. We use a new “verified” version of the SWE-Bench Multimodal benchmark, filtered to improve accuracy.
-
Software Testing: When debugging software, a first essential step is to identify the bug and generate tests that can reproduce the error. For this we use SWT-Bench.
-
Information Gathering: When performing software development, it is essential to gather information about APIs or other implementation details. We measure this using the GAIA benchmark.
All of these are implemented and open sourced in the OpenHands/benchmarks repo.
The Takeaways
Together with our release, we have benchmarked 9 language models from top providers such as Anthropic, OpenAI, Google, Deepseek, and Alibaba Qwen. Here are some takeaways for users of language models. Below we’ve plotted the models, and you can see more results on the OpenHands Index site.
Claude 4.5 Opus: The Overall Winner
Claude 4.5 Opus, the flagship model by Anthropic, has been a favorite for users of coding agents of all stripes. It was released in Nov 24, 2025, and as exemplified by AI expert Andrej Karpathy’s post, many have felt that it’s qualitatively much better than previous models.
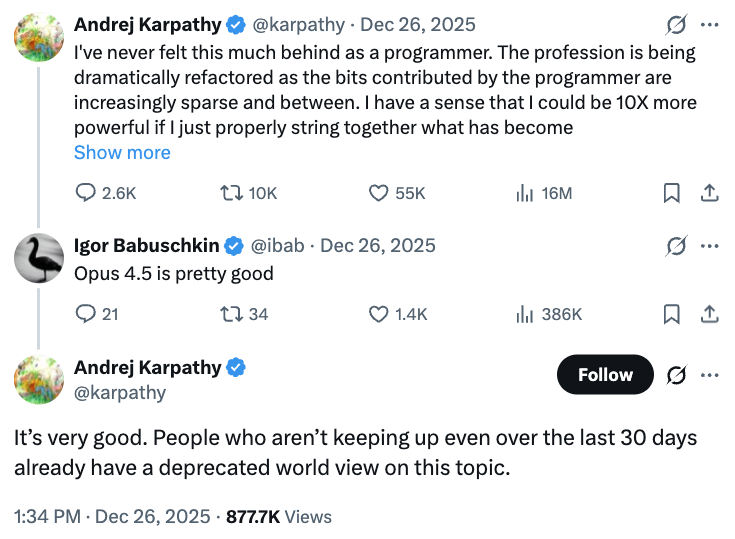
If you look at just the traditional benchmark of SWE-Bench Issue Resolution, the story is not very clear, there is only a small gap when comparing Opus to other models such as OpenAI’s gpt-5.2-codex, Google’s Gemini Flash, or DeepSeek v3.2 Reasoner.
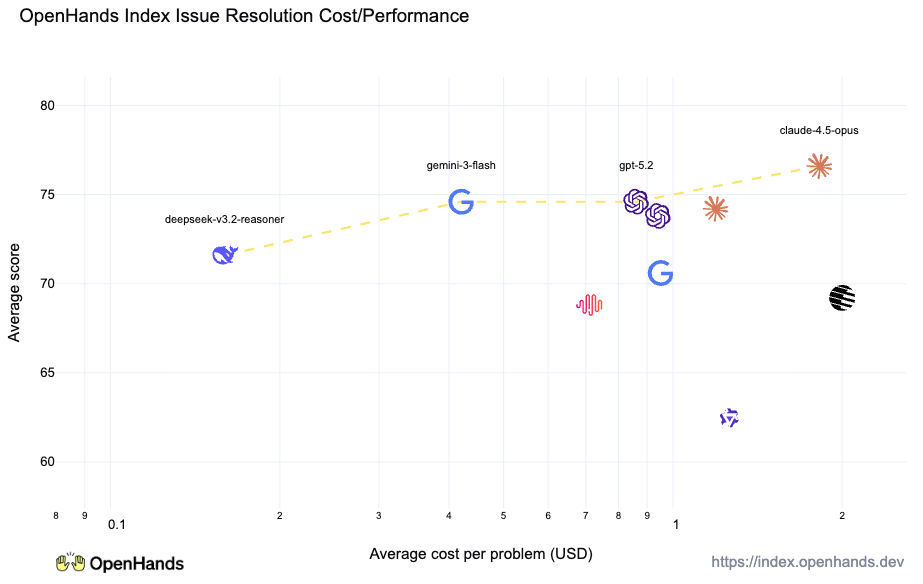
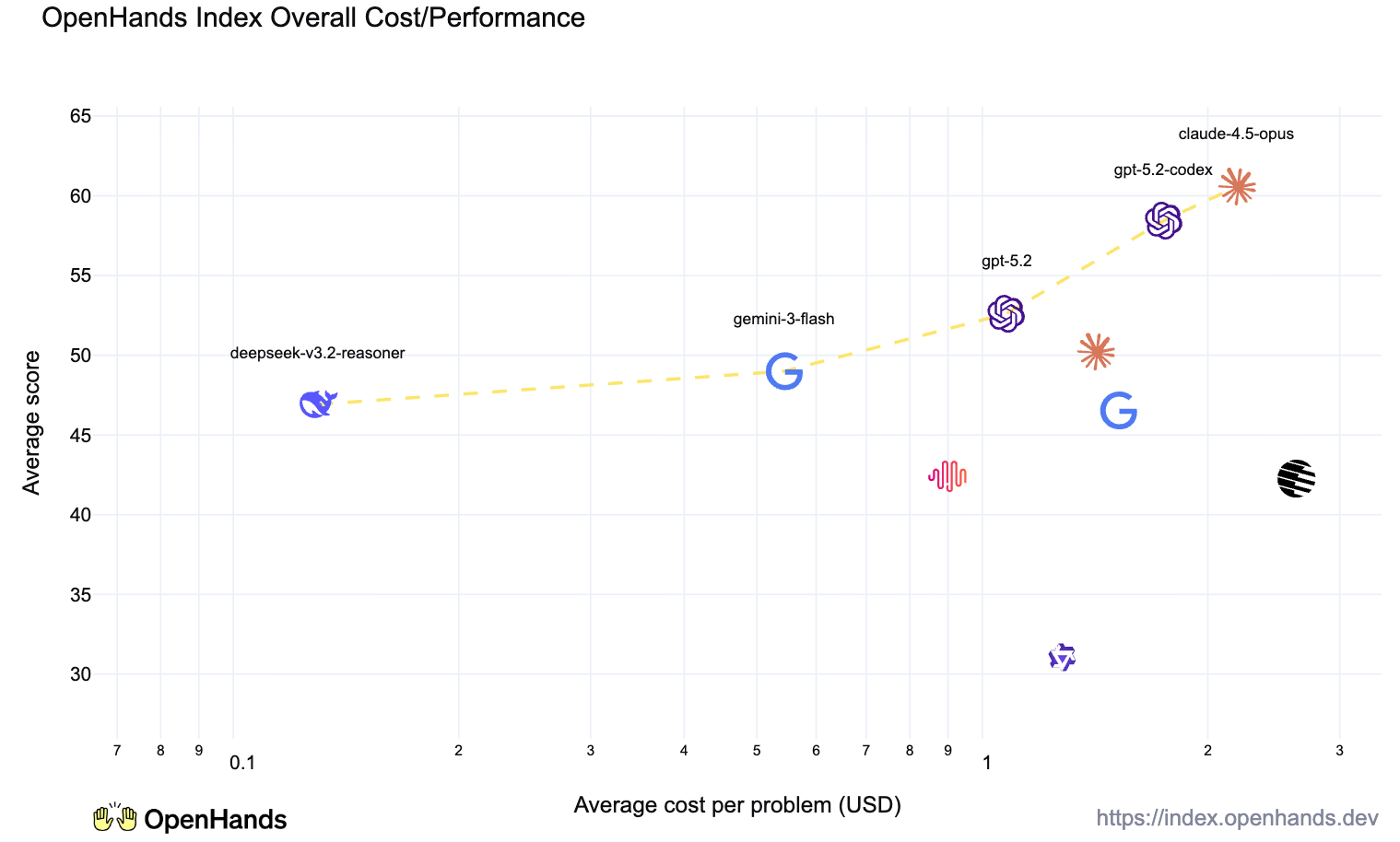
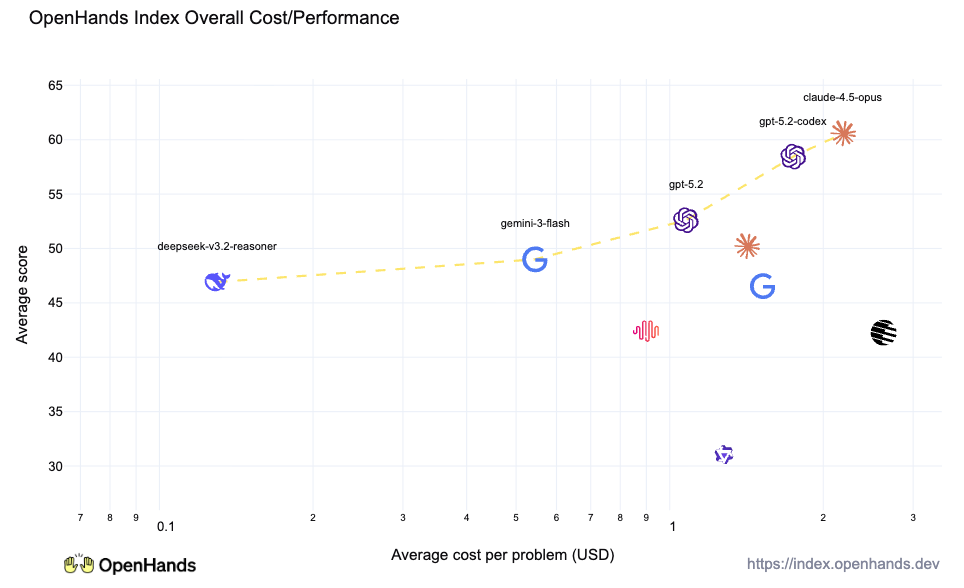
But when compared across the full OpenHands Index, the difference becomes clear, Claude Opus and OpenAI gpt-5.2-codex are clear leaders, while the others fall significantly behind.
In particular, it was the top system in resolving issues, frontend development, and writing unit tests to debug existing issues, and second in the other two categories, demonstrating strong across-the-board performance.

GPT 5.2 Codex: A Powerful Tool for Long-term Tasks
While Claude 4.5 Opus excels overall, GPT 5.2 Codex, OpenAI’s newly released model for coding tasks, was also quite powerful. It was a close second to Claude Opus overall at a reasonable price point, and it particularly excelled at long-horizon Greenfield development tasks, where it worked twice as long as Claude Opus, but achieved a significantly higher success rate.
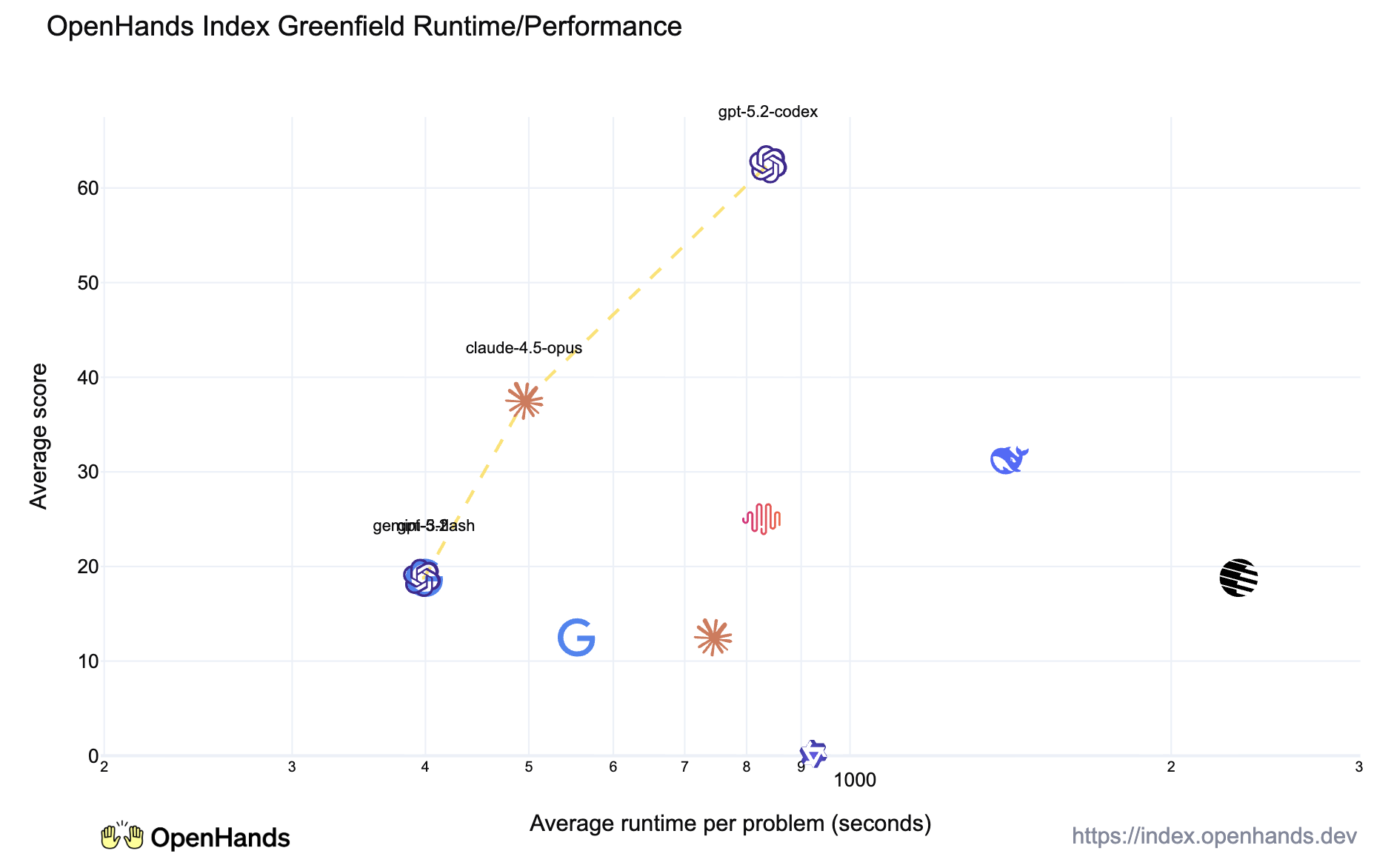
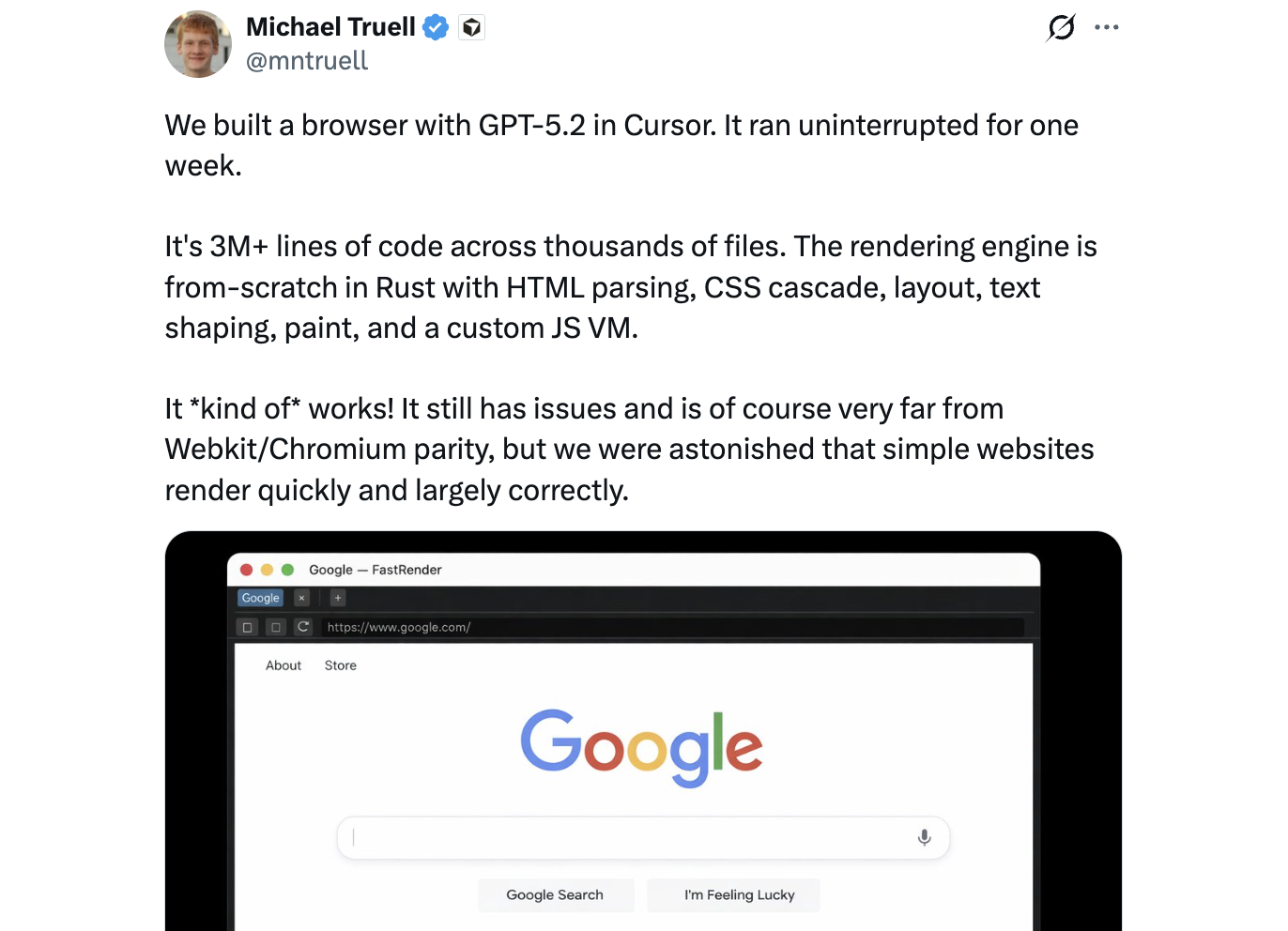
This is also reflects anecdotes from the community. For instance, Cursor CEO Michael Truell posted an anecdote that the model ran for a week and was able to build a somewhat functional web browser.
This indicates that GPT 5.2 Codex is a strong companion if you want to perform these sorts of these long-running tasks.
Affordable but Powerful: Gemini Flash, Deepseek 3.2 Reasoner
However, two characteristics of Claude Opus and GPT 5.2 is that they are somewhat pricy. Looking at the cost-accuracy curve, there were two other models that stand out.
-
Google Gemini comes in two editions, the larger Gemini 3 Pro and the smaller Gemini 3 Flash. Interestingly, Gemini 3 Flash actually exceeded the accuracy of Gemini 3 Pro on average. It was particularly good at standard code-based tasks such as issue resolution, greenfield development, and testing, but struggled on frontend development. Overall, Google’s models are strong contenders, but did not quite rise to the level of those from Anthropic or OpenAI.
-
Deepseek, the Chinese company which made a name for itself in creating the open-weight DeepSeek R1, a serious competitor to closed models, continues to put out strong models. Its latest DeepSeek-v3.2 was the strongest open model. It particularly shined at long-horizon greenfield development tasks.
Task Resolution Speed
In addition to cost, the efficiency with which tasks can be resolved is another important point — more speedy resolution means that users can form a tighter feedback loop with the agents.
Interestingly, and somewhat surprisingly, Claude 4.5 Opus, despite being a relatively large model (which means that it may take more compute generating each token), finished tasks much more quickly than others. Our qualitative experience using Opus backs this up however — it is particularly good at using parallel tool calls to quickly zero in on the task and solving it decisively.
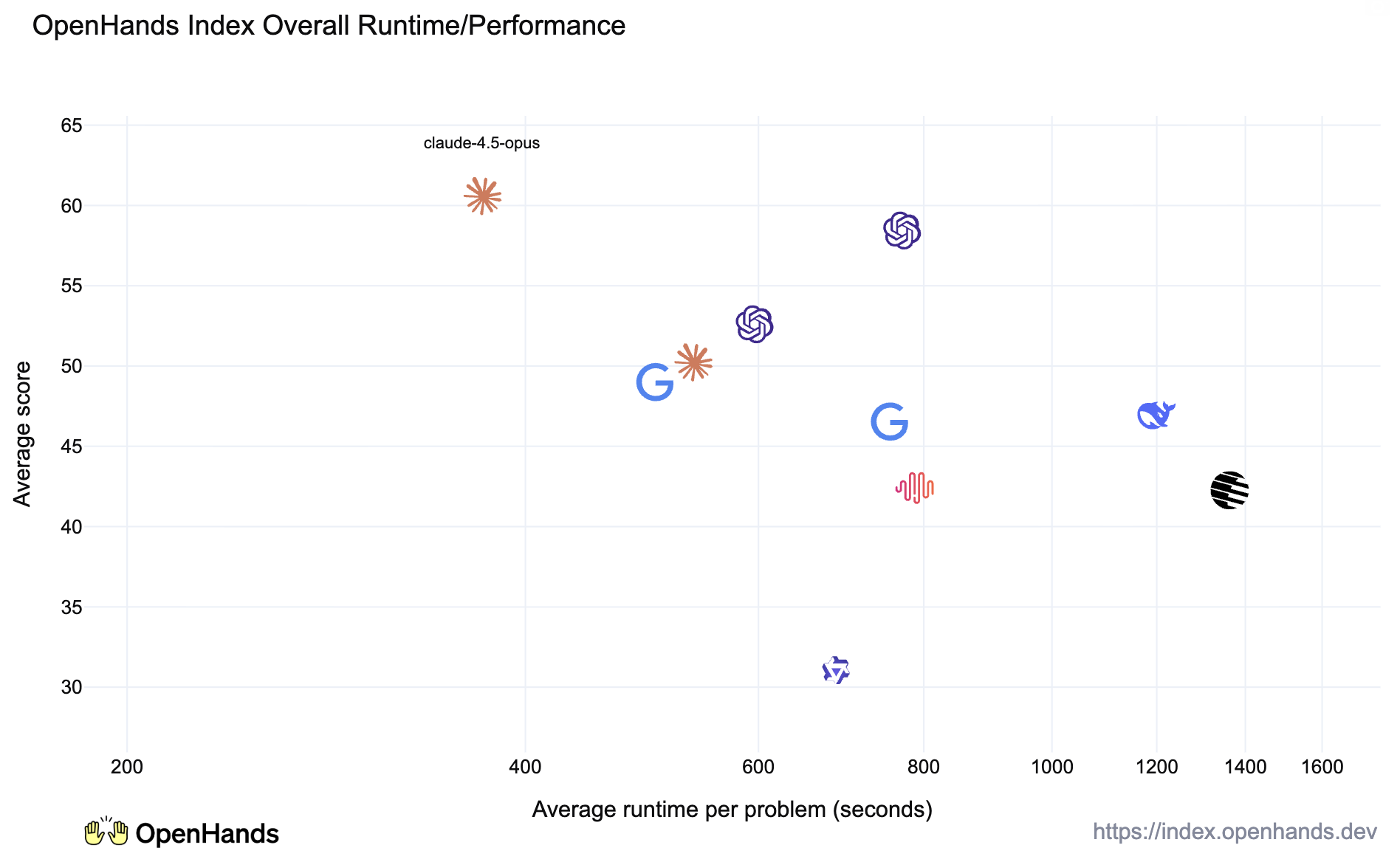
Another notable finding is that the closed models were generally quite a bit faster than the open models at solving tasks as well. This may reflect investments in efficient proprietary inference algorithms of model architectures that have not propagated back to open models.
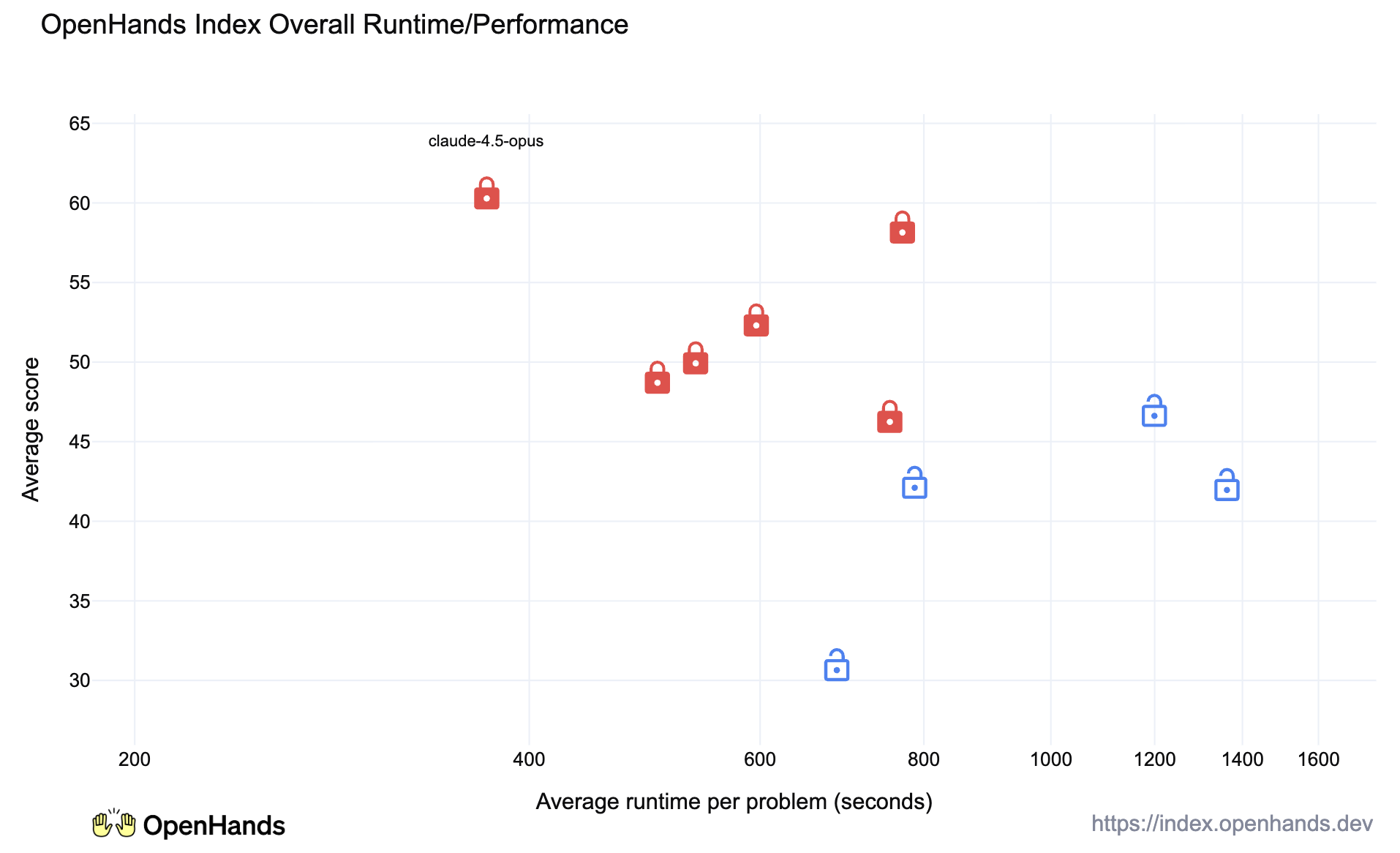
That being said, the open models were generally evaluated using inference providers using standard GPU hardware, and not specialized hardware such as Groq or Cerebras.
What’s Next?
This is just a taste of some of the interesting takeaways from the benchmark, so we’d encourage you to dive in to the data yourself on the OpenHands Index site!
Going forward, in the near future, we’re planning on adding more models of interest, both ones that have been released already, and new ones as they come out. In the somewhat farther future, we’re planning on refreshing the index with new benchmarks covering important aspects of software engineering.
Want to explore more? If you are:
-
A coding agent aficionado: please tell us what you think! Join our slack and join the
#dev-agentchannel to discuss or leave an issue on the OpenHands/openhands-index-results repo for results you’d like to see. You can also try out OpenHands through a GUI, CLI, or SDK. -
A language model developer: we’d love to help you benchmark your new models, please contact us via email or join our slack. Also, all our benchmarking code is released, so you can reproduce our results on your own if you wish.
-
A benchmark developer: If you have a good benchmark to test skills related to software engineering, we’d love to have you contribute a harness to our benchmarks repo, and we’ll consider adding them to the next version of the index.



Get useful insights in our blog
Insights and updates from the OpenHands team
Sign up for our newsletter for updates, events, and community insights.
OpenHands is the foundation for secure, transparent, model-agnostic coding agents - empowering every software team to build faster with full control.



