SWE-fficiency: Evaluating How to Fix Code, Not Just What to Fix
Written by
Jeffrey Ma and Vijay Janapa Reddi
Published on
This is a guest blog by Jeffrey Ma and Vijay Janapa Reddi of Harvard, introducing an exciting benchmark that uses OpenHands to tackle a new direction—performance engineering.
At OpenHands, the mission has always been to build AI agents that don't just "write code," but actually function as collaborative, high-judgment, and enterprise-ready teammates. To date, the field has mostly fixated on functional correctness: benchmarks like SWE-bench tell us if an agent can implement new features or fix a bug. But as any senior engineer knows, a system that works but is unacceptably slow is still a broken system.
This brings us to a key focus of our work: performance engineering. Performance engineering isn't about chasing a high score or a simple ranking; it's about localizing bottlenecks, navigating complex tradeoffs, and understanding system behavior well enough to make it lean. We believe that for AI agents to truly earn the title of "Senior Engineer," they must move beyond the "what" (functional fixes or new features) and master the "how" (efficiency and codebase maintainability).
We aren't just looking for agents that can pass a test, but rather agents that can think like performance engineers. That curiosity led us to identify a massive gap in how we evaluate agents today, and ultimately, to the creation of our benchmark, SWE-fficiency.
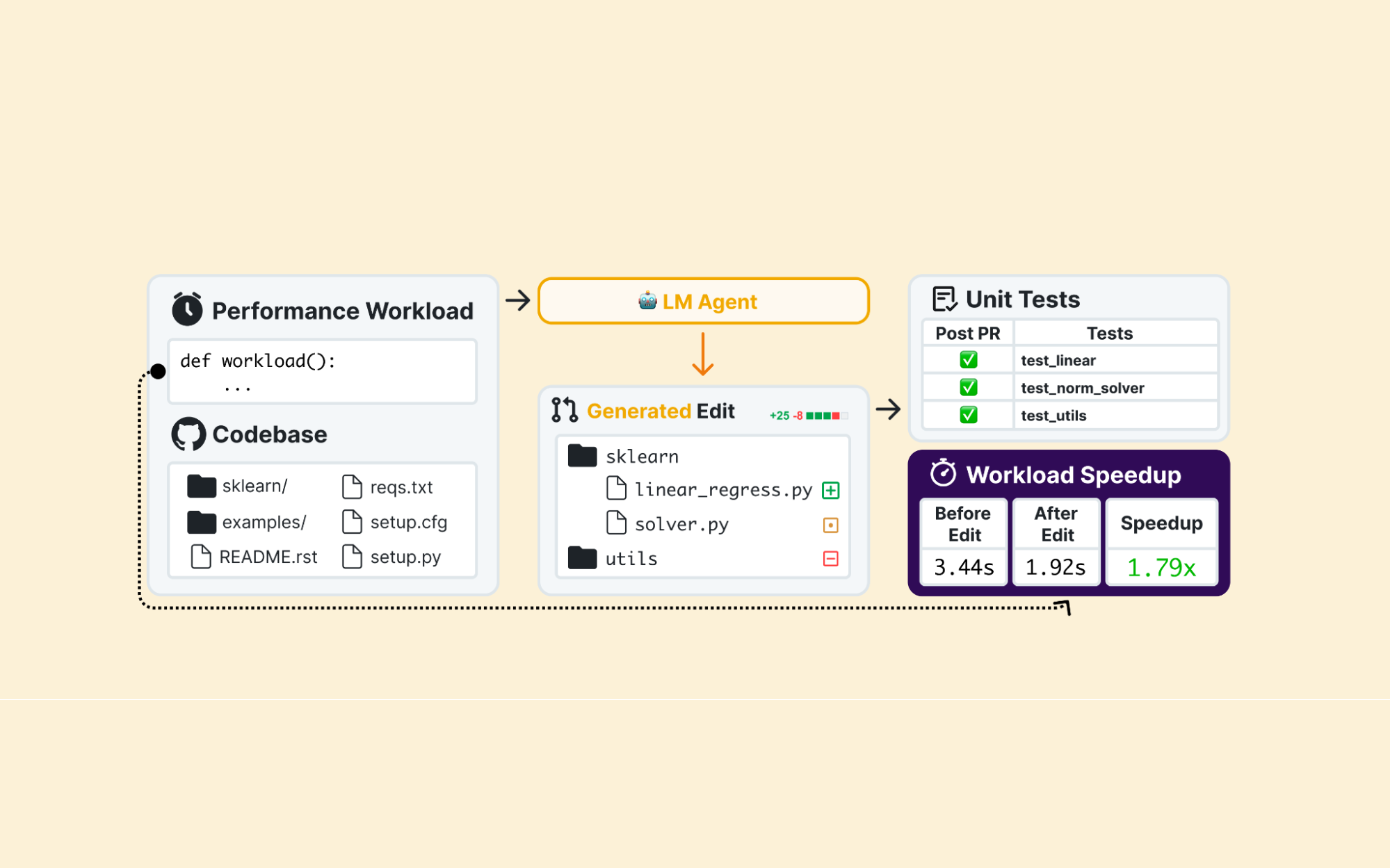
In the real world, "fixing" code isn't always about repairing a crash or adding a feature. Often, the code is correct, but it's slow. Optimizing a Pandas dataframe merge or speeding up a Numpy calculation doesn't require "fixing" a bug. Consequently, existing benchmarks prioritize what to fix (functional correctness). We wanted to measure if agents understand how to fix code (efficiency and optimization).
Implementing new features and functionality ultimately benefits hugely from humans in the loop, and we're super excited about works like ToM-SWE that examines how to improve how coding agents adapt to human preferences. For problems closer to the "how" of codebases, we're super keen to understand how well models and agents (like OpenHands) can operate asynchronously in the background for codebase maintainability and performance and keep the velocity of new feature development high.
The Gap: From "Fixing Bugs" to "Engineering Systems"
Existing benchmarks primarily prioritize a "fail-to-pass" workflow. You start with a failing test, and the agent's job is to modify source code to make it green. But performance engineering is inherently Pass-to-Pass. The code is already correct; the engineer's job is to make it better while preserving its existing behavior.
When we built SWE-fficiency (comprising 498 tasks across 9 major repositories like numpy, pandas, and scikit-learn), we realized that current evaluation pipelines actually filter out the most interesting engineering challenges. To build a bug-fix benchmark, you look for PRs that add new tests. In performance engineering, if you're doing it right, the input/output contract doesn't change, so you rarely introduce new functional tests.
To capture this, we built a novel pipeline that targets "invisible" improvements. We spent nearly 200 hours manually annotating performance workloads, reconstructing the same scripts that human experts used to expose bottlenecks.
The Metric: Why We Use "Speedup Ratio"
Binary success rates (Pass/Fail) don't work for performance. If an expert optimized a function by 10x and an agent only manages a 1.1x improvement, is that a "success"? Technically yes, but as an engineer, the difference is quite significant.
We introduced Speedup Ratio (SR) to measure how well an agent speedup matches human-expert performance. An SR of 1.0 or higher means the agent matched or exceeded the expert; anything less shows the gap to expert performance.
A Humbling Reality: What We Learned Using the OpenHands Harness
When we ran state-of-the-art models on SWE-fficiency using the OpenHands harness, the results were a wake-up call. On release, top agents achieved less than 0.23x the speedup of human experts.
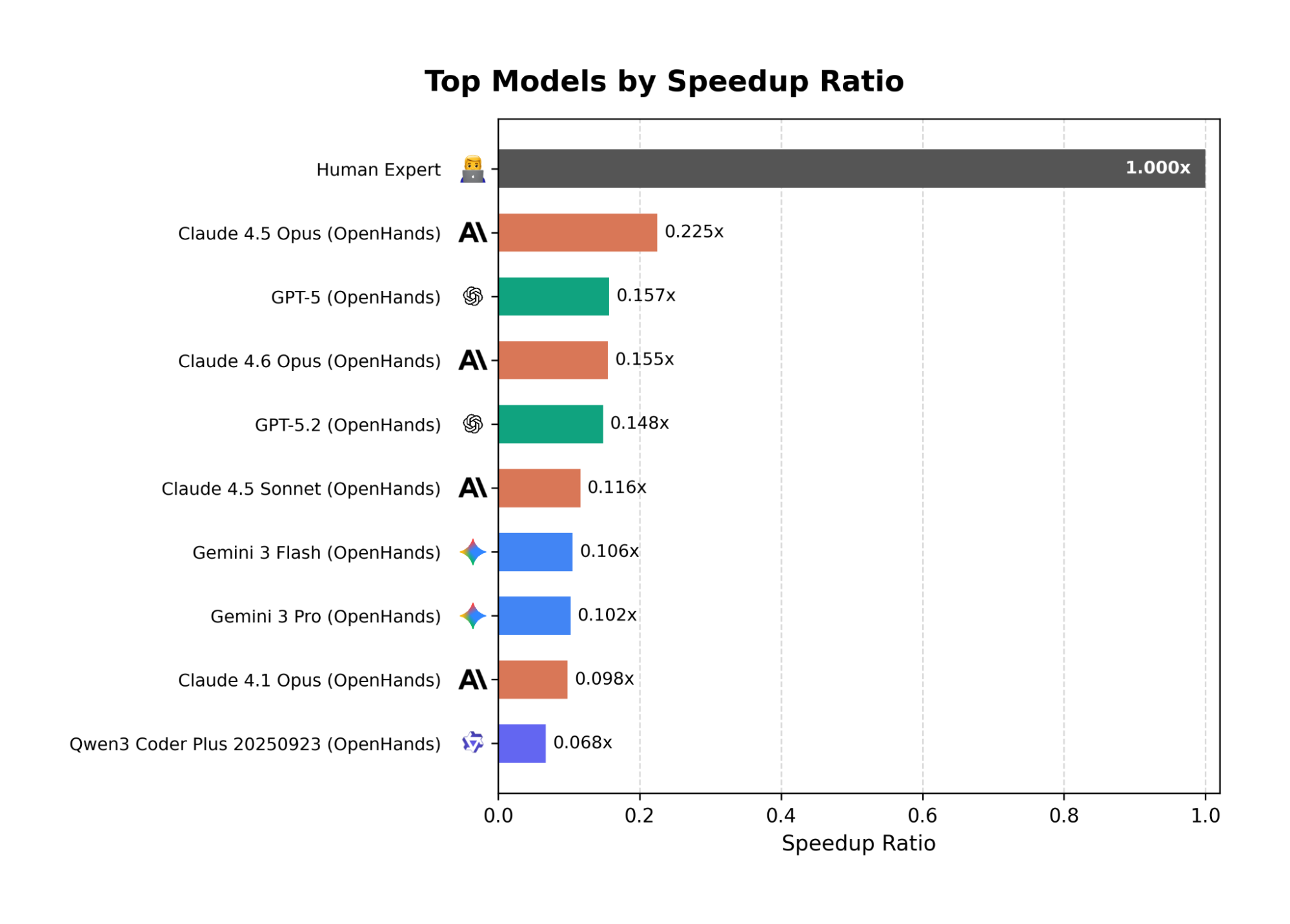
Why is this "Senior Engineer" skillset so hard for AI agents? We identified three systemic gaps:
-
The Localization Trap: Models struggle to find where the code is slow the same way that experts do. They choose the wrong file or function roughly 71% of the time. Often, they edit at the wrong call-stack level, missing the actual hot path.
-
Satisficing vs. Optimizing: We found a "satisficing" pattern: once a model finds a tiny, measurable speedup, it tends to stop rather than pushing for expert-level gains.
-
Blast Radius & Maintainability: Human experts tend to restructure code systemically—for example, moving loops to compiled code or using faster backends. Consequently, they also understand how they might be breaking correctness. Agents, however, prefer "monkey patches" and ad-hoc caches that are brittle and increase technical debt.
Why This Matters for the OpenHands Community
We built SWE-fficiency not just to have another leaderboard, but because we want agents that can operate asynchronously in the background to maintain codebases.
The future of software engineering isn't just about writing more code; it's about keeping the code we have healthy, fast, and scalable. If we want an agent we can trust to "clean up the codebase while the team sleeps," it must be able to reason about "blast radius" and performance tradeoffs as deeply as a human senior engineer.
SWE-fficiency is the first entry on the roadmap for that journey. It moves us past simple "bug-fixing" and toward the high-judgment, high-impact world of true, long-term codebase maintenance.
Check out the full paper on arXiv and explore our leaderboard and dataset at swefficiency.com.


Get useful insights in our blog
Insights and updates from the OpenHands team
Sign up for our newsletter for updates, events, and community insights.
OpenHands is the foundation for secure, transparent, model-agnostic coding agents - empowering every software team to build faster with full control.



