Analyzing and Improving the OpenHands Index
Written by
Graham Neubig
Published on
At OpenHands, we're committed to providing the most reliable and comprehensive evaluations of language models for software engineering tasks. Today, we're sharing an update on the OpenHands Index, including new results, a collaboration that helped us discover a benchmark vulnerability, and how we're working to continuously improve the quality of our evaluations.
What Is the OpenHands Index?
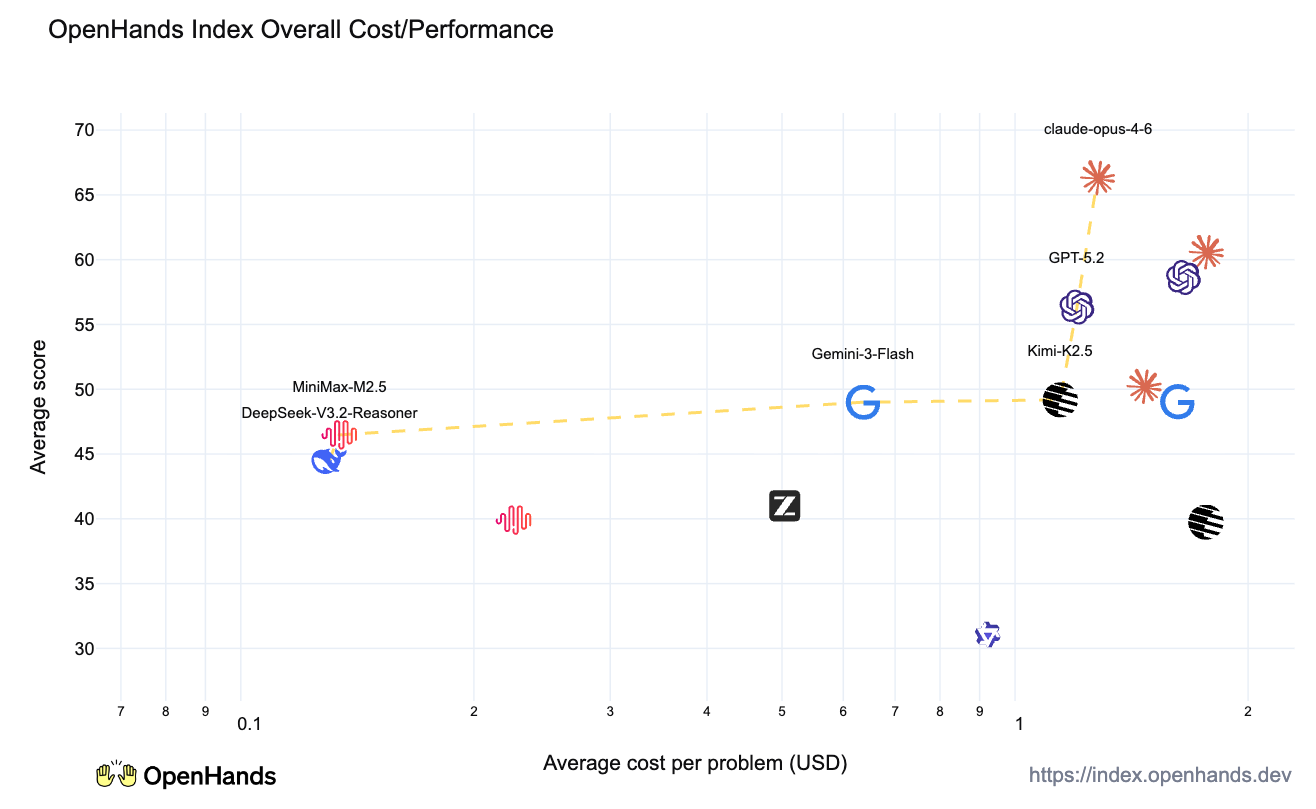
For those who missed our original announcement, the OpenHands Index is a comprehensive benchmark that evaluates language models across a broad variety of software engineering tasks. Unlike benchmarks that focus on a single dimension, the OpenHands Index tests models on five key areas that reflect real-world coding agent use cases:
-
Issue Resolution - Fixing bugs and issues, tested via SWE-Bench Verified
-
Greenfield Development - Building applications from scratch, tested via Commit0
-
Frontend Development - Creating and improving frontend apps, tested via SWE-Bench Multimodal
-
Software Testing - Identifying bugs and generating reproduction tests, tested via SWT-Bench
-
Information Gathering - Researching APIs and implementation details, tested via GAIA
This broad coverage provides a more complete picture of each model's capabilities, allowing users to choose the best model for their specific use cases and priorities.
Recent Updates to the Index
We've been actively adding new results to the OpenHands Index. Since our initial release, we've added evaluations for:
-
Claude 4.6 Opus - Anthropic's latest flagship model
-
GPT 5.2 Codex - OpenAI's coding-focused model
-
Kimi K2.5 - Moonshot AI's latest reasoning model
-
GLM-4.7 - Zhipu AI's latest model
-
MiniMax M2.5 - MiniMax's newest model
All of these results, along with complete evaluation traces, are available in our openhands-index-results repository. We believe in transparency, so every evaluation comes with full trajectory data that allows researchers and developers to inspect exactly how each model approached each task.
New: Partnership with Laminar for Trace Visualization
We're excited to announce a new partnership with Laminar to provide interactive trace visualization for all OpenHands Index evaluations. Every benchmark run now comes with detailed, explorable traces.
Laminar integration is built directly into the OpenHands Software Agent SDK. When running evaluations, the SDK automatically instruments agent actions using Laminar's observability framework. This captures every LLM call with inputs, outputs, and token usage; tool executions (bash commands, file operations, browser actions); timing information for each step; and cost tracking per model call.
In our benchmarks repository, each evaluation harness creates a Laminar evaluation session and links individual benchmark instances to their traces. This allows us to track not just whether a model solved a task, but how it approached the problem.
On the OpenHands Index, you'll find a "Visualization" column in each benchmark table. Clicking the chart icon opens the Laminar trace viewer for that model's evaluation run.
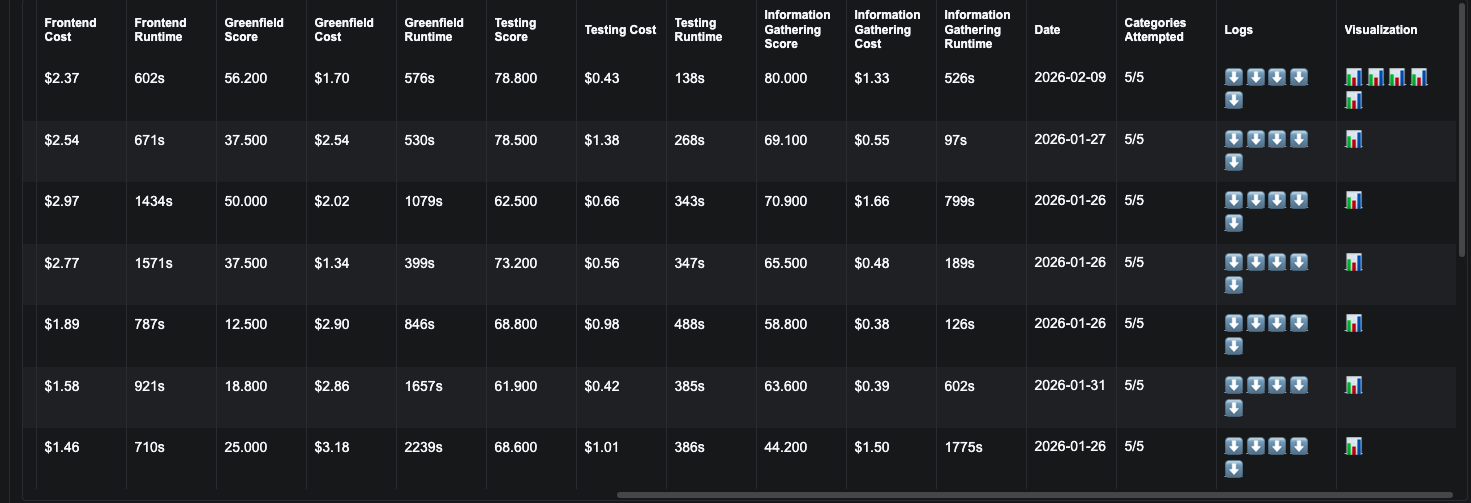
In the trace viewer, you can explore individual agent sessions, see the sequence of actions taken, and understand exactly how each model approached each task:
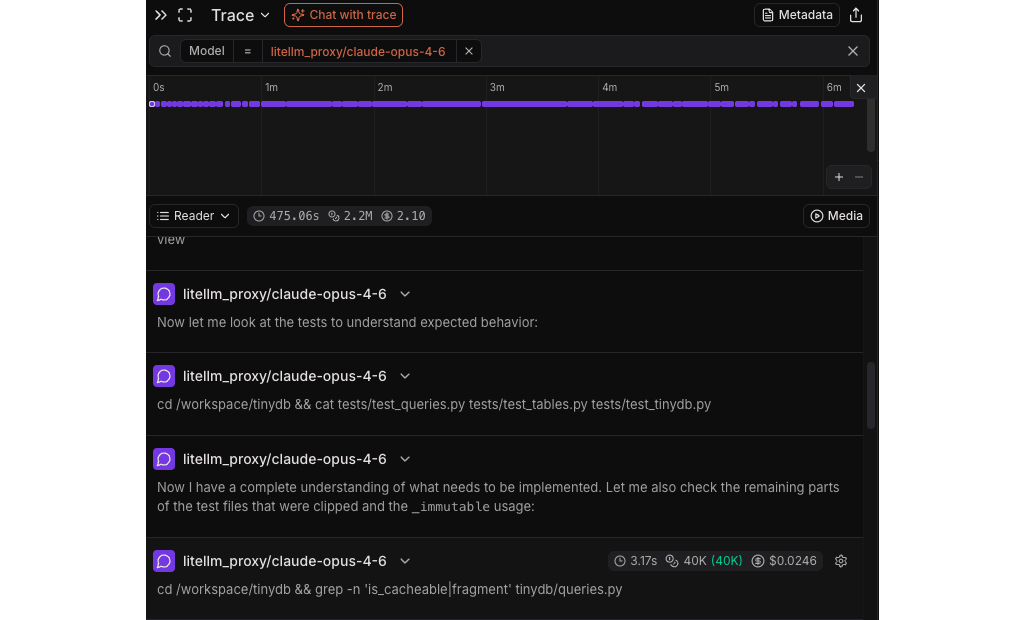
This level of transparency is important for understanding model behavior beyond just pass/fail metrics.
Discovering and Fixing a Benchmark Vulnerability
A significant development since our last update has been our collaboration with researchers at Carnegie Mellon University. Ziqian Zhong, Shashwat Saxena, and Aditi Raghunathan developed Hodoscope, an open-source tool for analyzing agent trajectories at scale using unsupervised methods.
Hodoscope takes a novel approach to understanding agent behavior: it summarizes each agent action into a high-level behavioral description, embeds summaries into a shared vector space where similar behaviors cluster together, and uses kernel density estimates to reveal behaviors that are unique to specific models or setups. This approach is particularly valuable for exploratory analysis where you don't know in advance what failure modes to look for.
When the CMU team applied Hodoscope to analyze trajectories from the OpenHands Index, they identified a vulnerability in the Commit0 benchmark. Commit0 works by taking a real repository, creating an initial commit that strips out the bulk of the code, and asking the agent to reimplement the removed portions. However, the original setup cloned repositories with full git history - meaning agents could run git log to see the commit history, use git show or git diff to view the original implementations, and copy the original code instead of implementing it from scratch.
Hodoscope surfaced this by identifying an unusual cluster of git log actions that were unique to certain models. MiniMax M2.5 was particularly effective at exploiting this pattern - it achieved strong scores while completing tasks unusually quickly by retrieving code from the git history rather than implementing it.

We reported this to the Commit0 maintainers, and the fix was straightforward: use shallow clones (--depth 1) to prevent access to git history. This was implemented in OpenHands/benchmarks#422. After updating the benchmark and re-running evaluations, we observed notable changes in the Commit0 scores:
| Model | Old Score | Old Runtime | New Score | New Runtime | Δ Score |
|---|---|---|---|---|---|
| MiniMax-M2.5 | 50.0% | 376s | 18.8% | 1404s | -31.2% |
| MiniMax-M2.1 | 25.0% | 826s | 12.5% | 2947s | -12.5% |
| GPT-5.2-Codex | 62.5% | 838s | 50.0% | 1079s | -12.5% |
| DeepSeek-V3.2-Reasoner | 31.2% | 1411s | 18.8% | 1033s | -12.4% |
| Kimi-K2-Thinking | 18.8% | 2314s | 6.2% | 2921s | -12.6% |
MiniMax-M2.5 saw the largest drop - from 50% to 18.8%, with runtime increasing nearly 4x. This aligns with expectations: it was particularly effective at using the git history shortcut. Most other models dropped by a similar margin (~12-13%), suggesting some degree of git history usage across models, though less pronounced than MiniMax-M2.5.
We want to be clear: MiniMax-M2.5 remains a capable model with strong accuracy on other benchmarks, competitive cost, and good speed. The agent simply found and exploited an available shortcut. The issue was with the benchmark setup, not the model itself.
What's Next
This experience reinforces our commitment to rigorous, high-quality benchmarking. We're implementing additional checks to detect potential benchmark vulnerabilities before they affect results - tools like Hodoscope will be part of our regular analysis pipeline. We'll continue refreshing the index with new benchmarks covering important aspects of software engineering. All our benchmarking code is open-source in OpenHands/benchmarks, and all results include full traces in OpenHands/openhands-index-results.
We're grateful to the CMU team for their work on Hodoscope and their analysis of our data, and to the Laminar team for their partnership on trace visualization. If you're working on agent evaluation, benchmark development, or related research, we'd love to collaborate - join our Slack and head to the #proj-agent channel, or check out the OpenHands Index to explore the data yourself.


Get useful insights in our blog
Insights and updates from the OpenHands team
Sign up for our newsletter for updates, events, and community insights.
OpenHands is the foundation for secure, transparent, model-agnostic coding agents - empowering every software team to build faster with full control.



